./rsc for research ./rocksdb for source analysis for rocksdb ./leveldb for source analysis for leveldb ./others for Others ./ctb for contributors ./help for help
K/V with LSM tree's Papers
记录正在读或者已经读过的Key Value键值存储系统的文章
Why K/V?
With the exponential growth of data volume,traditional relational database meets challenges in scalability in dealing with extremely large-scale data.
Key-value stores have become a fundamental part of the infrastructure for modern systems. Much like how file systems are an integral part of operating systems, distributed systems today depend on key-value stores for storage.
数据呈指数增长,非结构化半结构化数据占数据总量80%以上。传统的存储系统面临挑战,传统文件系统需要对海量小文件进行目录树管理,其扩展性和元数据管理成为性能瓶颈。传统的关系型数据库适用于结构化数据,采用表格结构来存储和管理数据,难以水平扩展。 其他的存储模型主要有列式存储,文档存储,图存储和键值存储几类。其中键值存储满足现代数据特征的需求:
- 数据类型灵活<--数据类型繁多
- 高可扩展性<--数据体量巨大
- 读写效率高<--数据生成快速
As an alternative, key-value(KV) store is widely used as the fundamental storage infrastructure in many applications.
Why LSM-tree?
According to the used index structures, KV stores can be categorized into hash index based design,B-tree based design and LSM-tree based design. Because hash index based design requires large memory and can not well support range query,and B-tree based design involves an abundance of random writes, so most modern KV stores use LSM-tree, e.g.,LevelDB(Google),RocksDB(Facebook),Dynamo(Amazon),Cassandra(Apache).
What's LSM-tree?
Log-Structured Merge-Tree

- 缓存排序,批量追加写
- 分层存储,容量递增
- 每层数据有序
Core idea:
-
充分利用磁盘的顺序写,先写入缓存,缓存区满后批量追加写入磁盘
-
保证每层数据的有序性。
数据在缓冲区内排序再Flush,保证SSTable内部有序。
外存中使用后台程序对层层写入的SSTable进行合并排序,保证SSTable间有序。
由于有序型,查找可以利用二分查找快速定位。
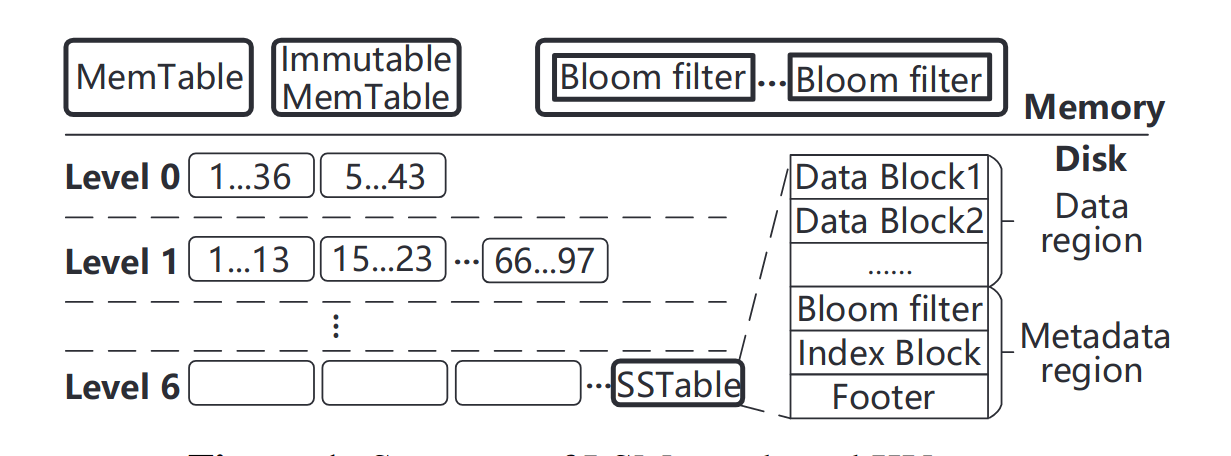
An LSM-tree based KV store is typically composed of two components. One resides in memory to cache KV pairs, and it includes a MemTable and an Immutable MemTable. The other is stored insecondary storage, which is divide into multiple levels consisting of multiple SSTables.
Each SSTable contains a set of sorted KV pairs and necessary metadata.When a level reachese its size limit its SSTables will be compacted into the next levle via compaction, which first reads out the SSTables in the two levels, then performs a merge sort, and finally writes back the new SSTables into the next level. (This is the reason that compaction induces severe write amplification.)
(Write amplification is the ratio of total write IO performed by the store to the total user data.)
When we lookup a KV pair,KV store needs to check multiple SSTables from the lowest level to the highest level until the key is found or all level have been checked.(This ie the reason that LSM-tree based KV store suffer from read amplication)
Furthermore, it is required to read multiple metadata blocks to really check whether a KV pair exists in one SSTable.
研究方向
- 存储引擎优化
- LSM-tree结构优化
- 读写性能:读写放大,均衡,尾延迟,I/O竞争
- SCAN优化
- 索引结构
- 学习索引
- 传统索引:Tree、Trie、Hash
- 分布式KV
- 容错结合:多副本/EC纠删码
- 均衡调度
- 新型介质
- PM非易失性内存
- 网络介质RDMA:分离式架构
- 云原生
- 应用结合
- DB:NewSQL
- 图
- 对象存储
- ...
Wisckey
WiscKey: Separating Keys from Values in SSD-conscious Storage
wisckey是一种基于LSM树的持久键值存储,基于LevelDB,论文的核心思路是将Key和Value分开以减少I/O的放大,同时充分利用了SSD 的顺序和随机访问特征。
Intro
LSM树比起其他index structures(比如B树)的优点是LSM树维护写入的顺序访问模式,B树上的small updates可能涉及到很多随机写入,因此在传统的HDD或者现有的SSD上效率都不是很高。
基于 LSM 的技术的成功与其在经典硬盘驱动器 (HDD) 上的使用密切相关。在 HDD 中,随机 I/O 比顺序 I/O 慢 100 倍以上 [43];因此,执行额外的顺序读取和写入以连续对键进行排序并启用高效查找代表了一个很好的权衡。
Motivation
然而,存储格局正在迅速变化,现代固态存储设备 (SSD) 在许多重要用例中正在取代 HDD。与HDD相比,SSD在性能和可靠性特性上有着根本的不同;在考虑键值存储系统设计时,我们认为以下三个差异至关重要。
-
SSD上的随机性能和顺序性能的差异并不像HDD那么大,因此执行大量顺序I/O以减少后续随机I/O的LSM树可能会不必要地浪费带宽。
-
SSD的内部并行度很高,SSD上的LSM必须精心设计才能利用这种并行性。
-
SSD可能会因为重复写入而导致磨损,而LSM树中的写放大会显著缩短SSD的寿命。
以上因素表明:LSM-tree在SSD需要进一步优化 => Wisckey (SSD-conscious)
Central idea
中心思想:键值分离(KV separation)
- <key,v_addr> 存储在LSM-tree中
- 值(values)独立存到log中
解耦LevelDB捆绑的键排序(Key Sorting)和垃圾回收(Garbage Collection),(即在排序的时候识别Invalid value并回收其内存)
好处:
- 降低由于排序时不必要的值移动(values movement)导致的写放大
- 降低LSM-tree的大小,==> fewer device reads and better caching during lookups.
分离KV导致的挑战和优化机遇
-
Value不再有序,因此scan(range query)的性能可能会被影响(Wisckey通过利用SSD设备中大量的内部并行性应对)
-
分离KV需要做garbage collect,回收那些invalid values占的空间(Wisckey提出一个在线且轻量的garbage collector,仅包含顺序IO,对前台负载影响很小)
-
KV的分离导致了crash consistency 的挑战,WiscKey利用文件系统的特性appends never result in garbage data on a crash,提供与现代LSMtree相同的一致性策略。
存在的不足
如果小的值是随机写入的,而大的数据集是按顺序进行范围查询的,那么wiskey的性能会比LevelDB差。(以不是真实世界用例辩解hh)
==> DiffKV 细粒度按值大小划分进行不同的处理。
Two Benchmarks
Differentiated Key-Value Storage Management for Balanced I/O Performance
DiffKV, a novel LSM-tree KV store that aims for balanced performance in writes, reads, and scans.
Intro
Key-value storage three main operations
-
writes, insert KV pairs
-
reads, retrieve the value of a single key
-
scans, retrieve the values over a key range
Efficiency of sequential I/Os && Data ordering for fast scans ---> Log-Structured-Merge-tree,
but suffer from high write and read amplifications.

Simple discription of LSM-tree storage structure
-
It stores KV pairs in entirety as multiple disk files, called SSTables, in multiple levels.
-
Two in-memory write buffers, MemTable, Immutable MemTable.
-
Flushing the Immutable MemTable to level L0 on disk with append-only writes.
-
All KV pairs in each of the levels from L1 to Ln are fully sorted by keys for fast scans.
L0 are unsorted across different SSTables for fast flushed.
(在L1至Ln的每一层中KV对都是按键全排序的;L0不保证SSTable之间的顺序, 但每个SSTable内部仍是有序的)
Write process
KV pair ---> MemTable --full-> Immutable MemTable (in-memory)
----------------------------------------|------------------------
| (out of memory)
L0 SSTable
|
n----full?----y---
| Compaction
L1 SSTable
|
full?
...
How to compact a SSTable S in Li into Li+1?
The KV store reads S and all SSTables in Li+1 that have overlapped key ranges with S,
then sorts all KV pairs by keys and creates new SSTables, then writes back into Li+1.
Read process
First, search in memory, not hit, then performs binary search in each level of the LSM-tree,
from L0 to Ln. 在每一层,使用Bloom filter 查看是否存在该KV pair.
Motivation
Two directions of LSM-tree optimization
-
Relax the fully-sorted nature in each level of the LSM-tree.
E.g. PebblesDB --- a fragmented LSM-tree
使用guards将每层划分为几个不相交的groups. 同一group下的SSTables中的键范围可能重叠。
将Li层中的一个组中的SSTables压缩至Li+1, 仅读取相应组中的SSTables,排序并存至Li+1,
不需读取Li+1层的与之有重叠的内容. 大大减轻了compaction overhead.
However, Sacrificing scan performance. (针对不同groups并行发射读—更多CPU资源消耗、有限提升)
-
KV separation
Keeping only keys in fully-sorted ordering in the LSM tree and performing value management in a dedicated storage area.
pros: LSM-tree size decreases, suited for large-size values KV workloads.
cons: For small-to-medium size values, degrades the scan performance. (Cause values over a key range are no longer fully sorted);
incurs extra garbage collection overhead.
可能的优化:
-
键和值的有序程度(the degrees of ordering in keys and values). fully sorted/ partially sorted/ unsorted.
-
针对不同大小的KV对的管理(KV pair: ..., large, medium, small, ...)
Methodology
DiffKV (区分的KV管理,既蕴含Key和Value的分离管理有序程度,又包含针对不同大小KV对的管理)
Two main ideas:
-
Carefully coordinate the differentiated management of the ordering for keys and values.
-
LSM-tree for <key, v_loc>, fully sorted
-
vTree for value management, partially-sorted values coordinate with respect to ordering of keys
Sorting of valuees in the vTree is triggered by the compaction of the LSM-tree.
-
-
Fine-grained KV separation, maintaining balanced performance under mixed workloads (KV pairs of different size groups)
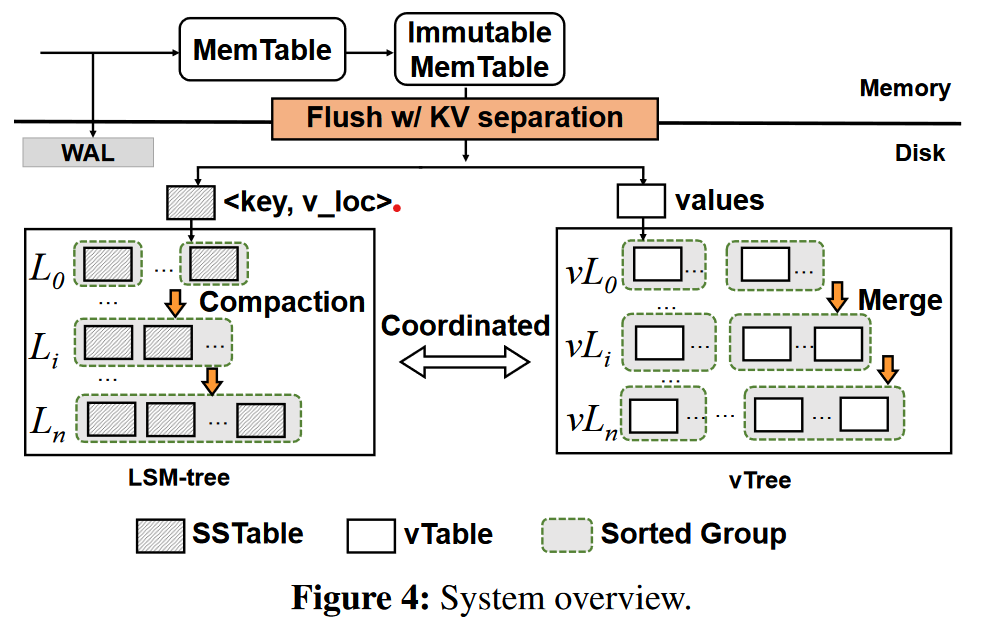
Features
vTable, DiffKV organizes values as fixed size vTables. composed of:
-
data area, values of KV pairs in a sorted order based on their keys
-
metadata area, e.g. data size of vTable / smallest and largest keys of the values
Sorted group, a collection of vTables. The key ranges of any two vTables in a sorted group have no overlaps.
In DiffKV, all vTables generated in one flush form a sorted group,
use the number of sorted groups is an indicator of the degree of ordering in the vTree.(以vTree中有序组的个数来指示有序程度)
vTree
| vL0 ]
|[***sg1]..[***sg8] vL1 -- level ]
... ] vtree
| vLn ]
// vtree consists of levels
level consists of sorted groups (not necessarily sorted)
sorted group consists of vTables
vTable consist of values
Merge operations are used to keep partially-sorted ordering for values which was triggered by
compaction operations in the LSM-tree in a coordinated manner. --- compaction-triggered merge
Two benefits from ctm:
-
efficient to identify valid values;
-
reduce overhead needed to maintain the latest value locations.
Further Merge Optimizations
每个compaction一个merge,太多了。
- Lazy merge, 将vL0,...,vLn-2视作a single level,任何来自L0,...,Ln-2的压缩不会引发归并,
除非值需要归并到vLn-1.
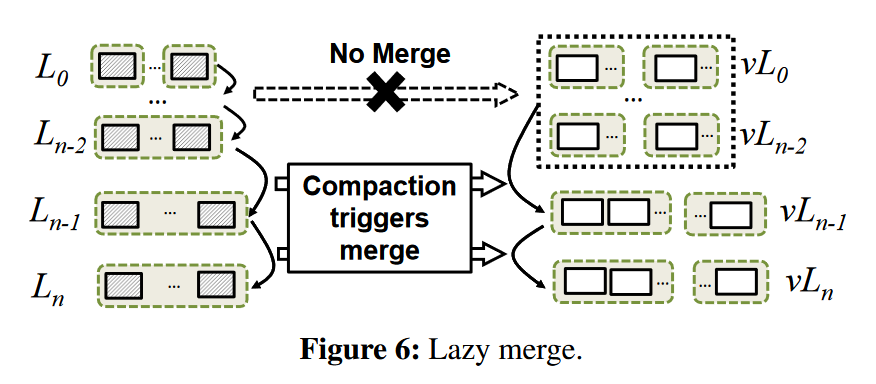
-
Scan-optimized merge
找出与许多其他vtables有重叠键范围的vtable,使之参与合并过程,增加vTree中值的有序度。
垃圾回收
回收无效值所占用的空间(在LSM-tree中,通过压缩回收无效值)
小优化:state awareness, Lazy GC 降低垃圾回收开销
细粒度的KV分离
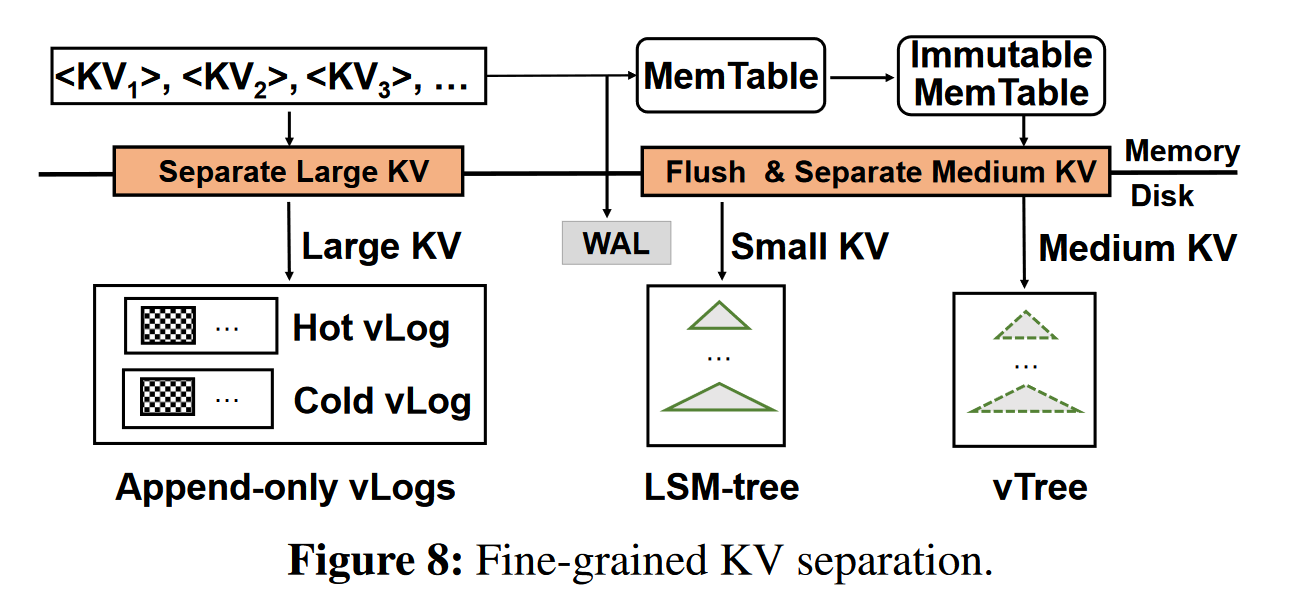
根据值的大小分为large, medium, small
-
large KV pairs, 采用hotness-aware multi-log(vLogs)
-
medium, values in vTree, <key, v_loc> in LSM-tree
-
small, no KV separation, all in LSM-tree
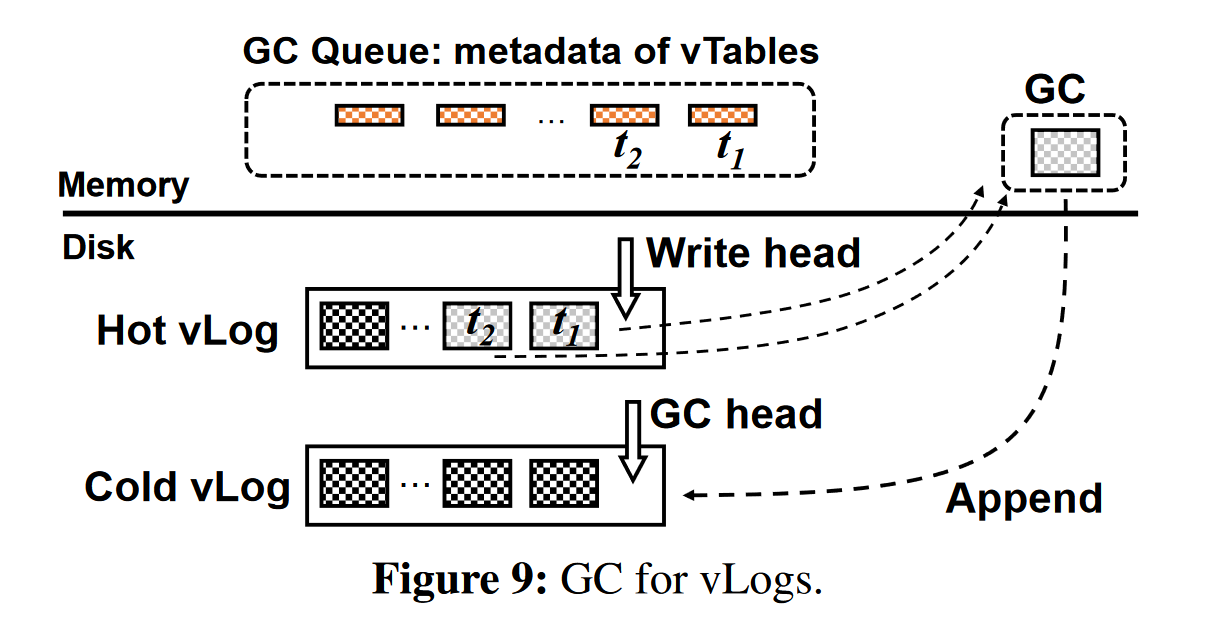
vLog: 被设计成一个简单的循环append-only log,它由一组未排序的vtable组成。
热感知 vLogs: Hot vLog (Write head), Cold vLog(GC head)
ElasticBF
Bloom filter
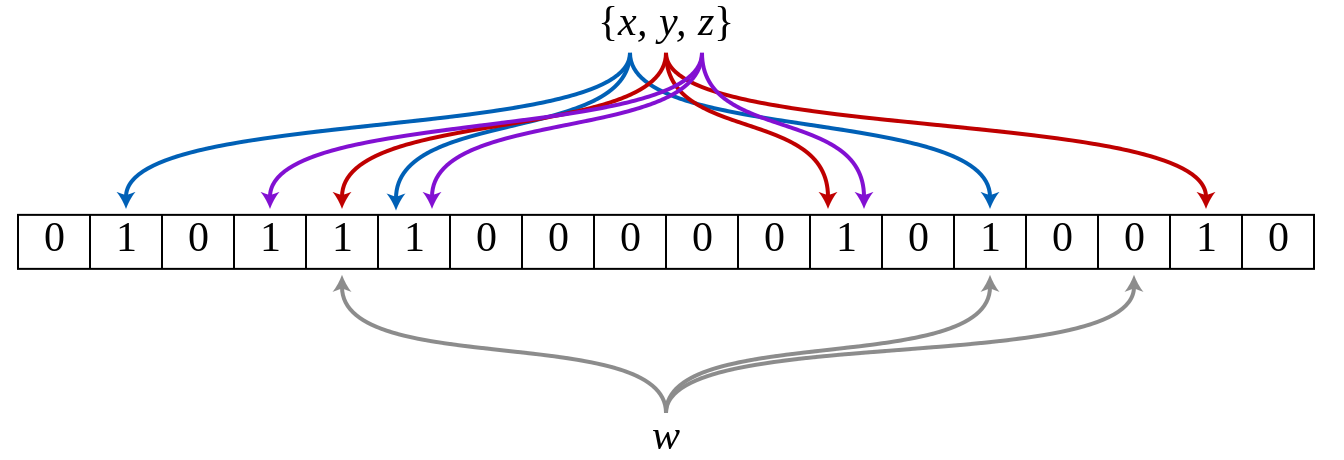
A Bloom filter is a space-efficient probabilistic data structure, conceived by Burton Howard Bloom in 1970, that is used to test whether an element is a member of a set. False positive matches are possible, but false negatives are not – in other words, a query returns either "possibly in set" or "definitely not in set".
An empty Bloom filter is a bit array of m bits, all set to 0. There must also be k different hash functions defined, each of which maps or hashes some set element to one of the m array positions, generating a uniform random distribution. Typically, k is a small constant which depends on the desired false error rate ε, while m is proportional to k and the number of elements to be added.
To add an element, feed it to each of the k hash functions to get k array positions. Set the bits at all these positions to 1.
To query for an element (test whether it is in the set), feed it to each of the k hash functions to get k array positions. If any of the bits at these positions is 0, the element is definitely not in the set; if it were, then all the bits would have been set to 1 when it was inserted. If all are 1, then either the element is in the set, or the bits have by chance been set to 1 during the insertion of other elements, resulting in a false positive. In a simple Bloom filter, there is no way to distinguish between the two cases, but more advanced techniques can address this problem.
Bloom filters also have the unusual property that the time needed either to add items or to check whether an item is in the set is a fixed constant, O(k), completely independent of the number of items already in the set. No other constant-space set data structure has this property, but the average access time of sparse hash tables can make them faster in practice than some Bloom filters. In a hardware implementation, however, the Bloom filter shines because its k lookups are independent and can be parallelized .
See https://en.wikipedia.org/wiki/Bloom_filter to know more about Bloom Filter.
ElasticBF: Elastic Bloom Filter with Hotness Awareness for Boosting Read Performance in Large Key-Value Stores
Core idea:
We observe that access skewness is very common among SSTables or even small-sized segments within each SSTable.
To leverage this skewness feature, we develop ElasticBF, a fine-grained heterogerneous Bloom filter management scheme with dynamic adjustment according to data hotness.
一种细粒度的异构BloomFilter,可以根据数据热度进行动态调整。BF的设计和基于LSM-tree的KV存储是正交的,便于集成到已有的KV系统上。
How to get this idea?
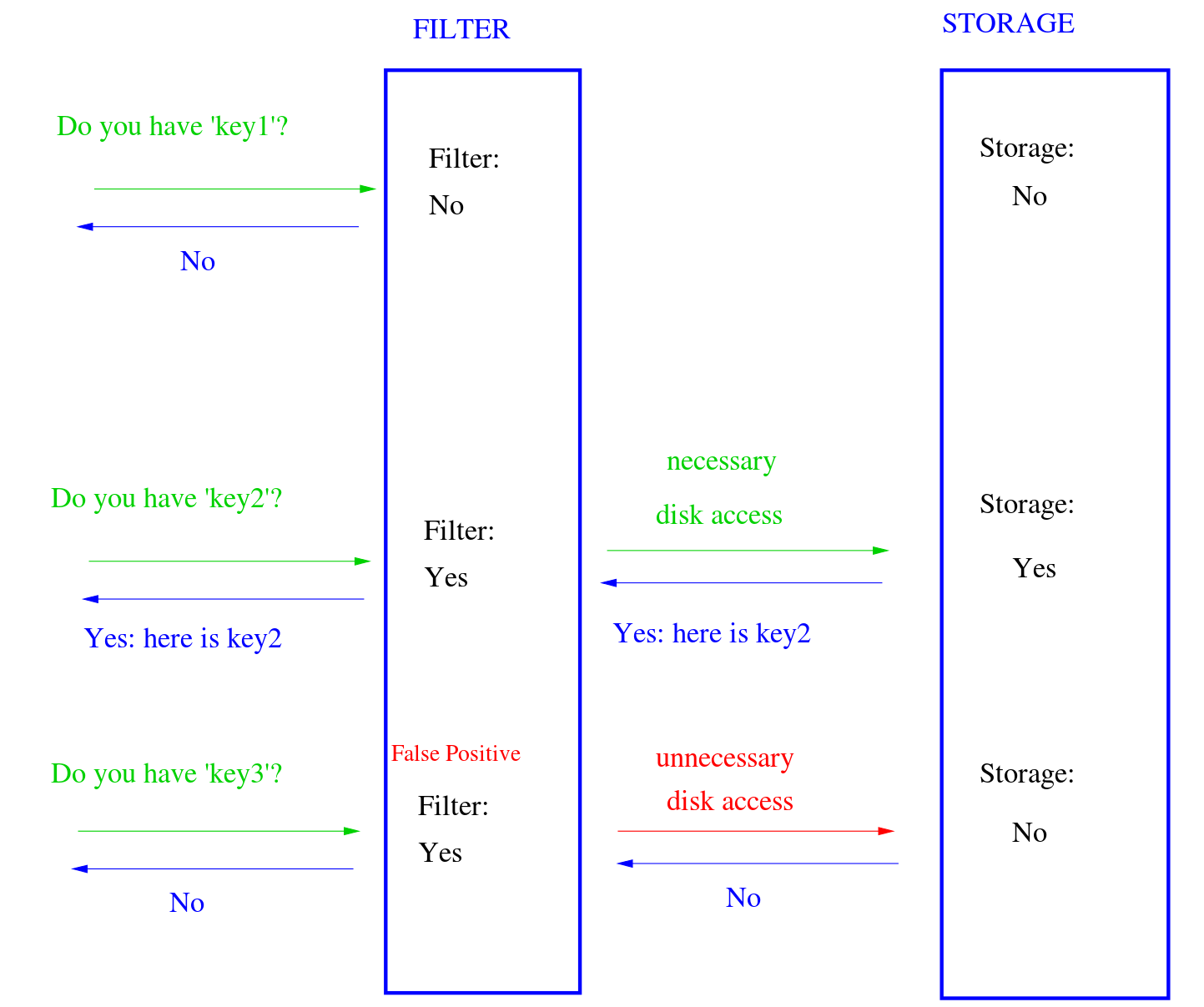
LSM-tree结构的KV存储有着严重的写放大(300x),当在KV存储中查找一个KV对时,需要从最低层次的level0一直检查到最高层次的leveln,直到找到该KV对或者所有的level都被检查完。每次检查KV到底在不在SSTable中时,需要读取多个SSTable中的元数据块。
为了减少检查多个SSTable带来的额外I/O,现代KV系统会利用Bloomfilter来快速检查在单个SSTable中是否存在某个KV对。
Bloomfilter虽然能快速检查,但存在假阳性现象,可能SSTable中不存在该KV对但仍会返回阳性,这就会产生不必要的I/O。
论文里为了验证BF的假阳率会产生多少不必要的I/O,在100GB的4-bits-per-key的KV存储中测试,结果是平均每次查找会检查7.6个SSTable,但其中1.3个是由于BF假阳造成的不必要I/O访问。
这个作者的思路很多时候都是,感觉哪个地方有能做的优化,那么设置某个实验来验证这个优化是否有效果,有多大效果。同时这个实验也是一种证明解决该问题存在合理的Motivation的方式,也让审稿人知道这个idea不是空穴来风拍脑子想出来的,而是来源于实践
传统的解决BF假阳率的办法是给每个key分配更多的bit,但这会使得BF的空间显著增大,10TB的KV,其中KV对大小100B,BF使用10bits-per-key的话,需要占用128GB的空间。
实验给出来说明问题存在后, 先提出传统的方法,再提出新方法
BF是个好东西,但是它的一个隐含假设其实是,对所有KV对的访问都是平均的,这样多个Hash出来的BF才不会浪费,也就是说,对所有KV的访问都有着一样的误报率。
但实际的使用中,数据存在明显的冷热数据区别,一些KV对是热数据,会被频繁访问,其他大部分的KV都很少被访问。
那么思路就在这里了,BF不能太大,即每Key的bit数不能太高;同时提高每key的bit数可以降低假阳率;数据还有冷热之分。那我们为什么不能在保证BF大小限制的情况下,给那些热的KV对分配更多的bit,减少热数据的假阳率呢?
热数据假阳率的降低会减少热数据的SSTable访问次数,减少磁盘的访问次数,提高上层应用的性能。
给出思路之后,给出引入新方法带来的代价
BF的设置不是那么容易调节的
-
不同的level有着不同的访问不均匀性。尽管更低级别的KV对通常访问频率更高,但仍然有一部分更高level的SSTable明显比低level的SSTable更热。(论文2.2给出实验说明)
-
即使在同一个SSTable中KV对,访问不均匀性也很严重。(2.2实验说明)
-
最后,KV对的热点随着上层应用的运行会动态变化。
Monkey论文中提出的不均匀机制是他观察到更低级别的KV对访问平均来说比更高层次的更多,所以Monkey在BF中给更低level分配更多的位。但Monkey没有发现同一level里的访问也是不均匀的(讲了一把同行没想到的点,不过可能作者思路就是从Monkey来的),而且不能根据数据热点动态调整。
ElasticBF是一种细粒度弹性的Bloom filter管理机制。最基本的idea就是在构建SSTable时为每一组KV对分配多个小型的Bloomfilter,这些Bloomfiler驻留在磁盘中,并根据KV对的热度动态加载到内存中激活。
为了实现动态加载,需要解决:
-
如何在低开销的情况下精确评估和记录KV对的热度
-
如何在低开销的情况下根据热度动态改变Bloomfilter的能力
-
在compaction重组SSTable的时候如何以较低的元数据开销高效继承上一层SSTable的热度。
Solution
ElasticBF的解决方案:
- fine-grained allocation:
KV对的热度在同一SSTable的不同范围内差异显著。因此将每个SSTable分成不同的段,在可接受存储和CPU开销下测量并记录热度,从而获得相对准确的热度估计,并实现细粒度的Bloomfilter分配。
- hotness inheritance:
通过继承过时的SSTables来估计compaction期间新SSTables的访问频率。避免由于compaction造成的热度频繁冷启动热度,持续提高读的性能。
其实是写了个compaction的时候热度处理的策略,这里可以参考,即如何统计管理SSTable内的热度,可能能用在其他地方。
- in-memory management optimization。
使用多队列的机制来管理内存中的Bloomfilter,使用并行的I/O来加速调整。以一个“较小” 的CPU开销,根据KV对的热度来动态调整内存中的Bloomfilter.
CPU开销真的较小吗?
Test Result
测试结果: LevelDB,RocksD,PebblesDB,read thoughtput 2.34x 2.35x 2.58x, respectively,while keeps almost the same write performance.
mixed reads and writes, ElasticBF reduces read latency by 38.9%-51.8% without affecting writes.
compared with Monkey,ElasticBF achieves up to 2.20x throughput.
Design
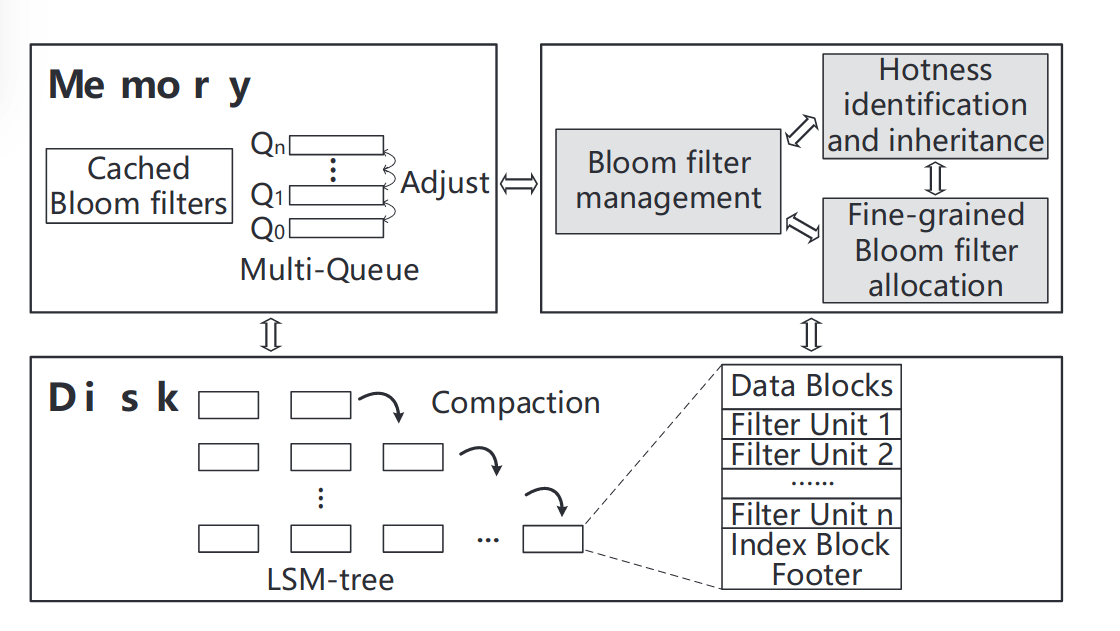
ElasticBF主要包含三部分
-
细粒度的BF分配,fine-grained Bloom filter allocation
-
热度感知和继承,hotness identification and inheritance
-
内存BF管理,Bloom filter management in memory
对于细粒度BF分配,首先需要解决,每个SSTable应该分配多少Bloom filter,每一个filter应该分配多少bit,以实现低误报率和低内存使用。也需要细致地设计低I/O开销的数据结构和管理机制。
对于热度感知,论文的目标是以较低开销实现相对准确的热度估计。
热度继承是为了避免在compaction之后热度感知的冷启动。
内存中Bloomfilter的管理是根据热度有效地调整Bloomfilter
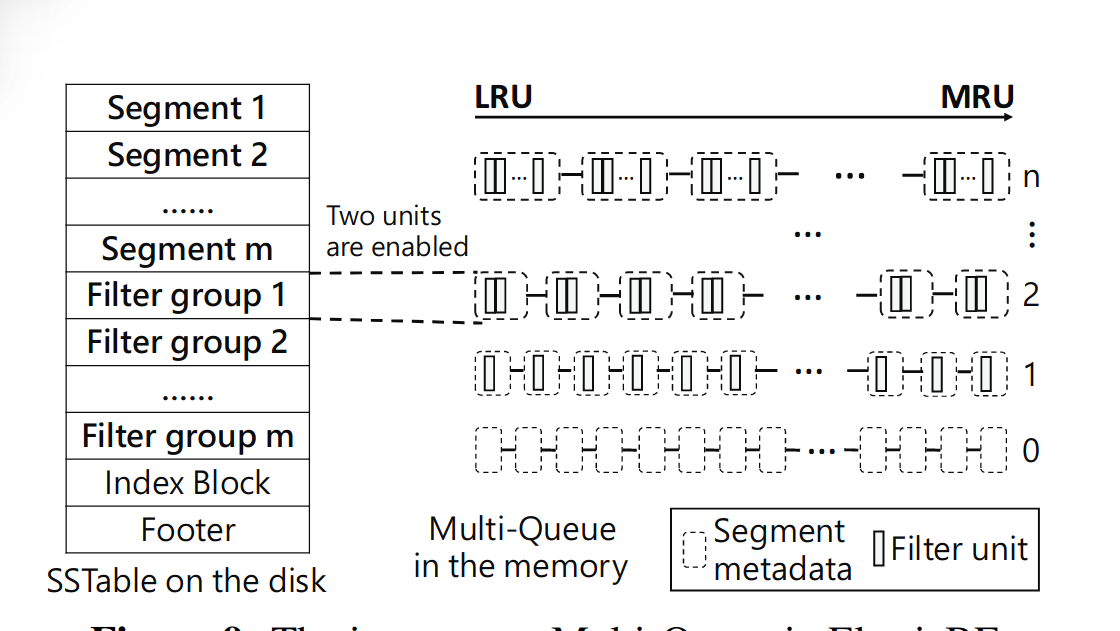
整体的具体实现可以用这张图来讲清楚,首先我们将原来SSTable存KV对的数据区域分成m个Segment,每个Segment对应一个Filter group,而每个Filter group由若干个filter unit组成。这是在二级存储中的SSTable的改动。这是细粒度管理的基础结构。
接着为每一个Segment都设置一个热度变量,在上层应用运行的过程中动态改变,由此我们可以得到每个Segment的热度,同时设立热度继承机制,以在compaction之后避免新SSTable冷启动造成性能下降。
最后来看内存中添加的新结构,内存中维护一个多级队列,使用LRU调度。每次找key时lookup到某个SSTable,先把Filtergroup调到内存中,看这些Filter group里面能不能命中,开始时可能每个Segment对应的Filtergroup有几个默认的filter unit载入。运行一段时间后,根据热度数据,对热度高的Segment,将其提升到多级队列的高层,Filter group对应在多级队列的第i层,那么该Filtergroup对应的Segment就会有i个filter unit载入内存中。提到高层,使用的filter unit就多了,这样就会降低误报率。运行的时候,对于热度下降的Segment,会尝试将其Filtergroup移动到多级队列的下级,节省资源。
以上就是ElasticBF三个部分具体实现的简述
Q&A
拆开的filter的与原来的Bloomfilter有什么联系?
ElasticBF给每个SSTable用多个不同的独立Hash函数产生多个Bloomfilter,每个filter的位数小于bits-per-key,叫filter unit。 一个SSTable里的所有filter unit被称为filter group。假设来了一个key的查询,因为在一个group里的filter unit都是独立的,所以只要有一个filter单元返回negative,那么查询的key就必定不在这个SSTable中。只有所有的filter单元返回positive,,才需要读出SSTable来从中读取key。 可以证明,总共有着b bits-per-key的filter group的误报率和有着b bits-per-key的single Bloom filter误报率是相同的。
热度继承具体怎么做的?
热度的继承如图右侧所示,选取上一层的SSTable中有数据overlap的那些Segment对应的热度,做平均后给到新的SSTable,简单有效。
PebblesDB
PebblesDB:Building Key-Value Stores using Fragmented Log-Structured Merge Trees
写放大问题的根源是LSM-tree的数据结构本身。论文提出一种类似与Skip Lists的新LSM-tree数据结构,Fragment Log-Structured Merge Trees(FLSM)。FLSM引入了Guard的概念来组织日志,避免在同一级别重写数据。
How to get this idea?
LSM-tree结构需要在维护数据的排序,从而实现数据的高效查询。但是插入新的数据时,现有的数据会被读出来重写以维持排序,从而会导致大量的写IO。
当写入一个KV导致第i层和第i+1 层的Compaction发生时,会把i+1层中和i层有数据重叠的SSTable读出来,和i层做排序后再写回i+1层。这个过程会在i+1层先读出后写入,在同一Level重写数据。
其实必要的数据写入就是i层写满了,把i层写到下一层。如果有一种方法,compaction 的时候只需要把上一层的数据写到下一层,不要把下层的数据读出再写入,那么就可以减少写放大。这就是Pebble的思路。
注意Wisckey的思路是把K和V分离,减少每一层的写入,PebblesDB是减少第i+1层的数据读出再写回,上一层次还是要把K和V一起写到下一层。把这两者综合一下。这里如果先做KV的分离,再用Pebbles的优化,引入的代价可能更大,应该也不会这么做。如果先用Pebbles的优化,再把KV分开,那这里就要考虑KV对的实际大小,这就是DiffKV的思路。
Realize this idea
PebblesDB思路的具体实现是借助类似跳表的结构,如下图所示。

传统的LSM-tree树,有以下基本操作:
Get()
Put()
Iterators()
有Seek()和Next(),Seek(k)找到大于等于k的最小元素,Next()找到下一个元素。
RangeQuery()
在每一层中,都在对应的SSTable中安排一个Iterator,最后将每一层的结果Merge得到范围查询的结果。
FLSM
在FLSM结构中,将每一层的SSTable片段化,安排在Guard中,Guard之间没有overlap,Guard内的SSTable允许有overlap,插入KV对时有一定概率插入一个Guard。
这种结构Get的时候,会从Level 0 到Level n,每层读取的时候先在Guard中二分搜索到某个Guard,然后再在这个Guard中的每个SSTable中分别进行二分搜索。(或者先经过Bloomfilter),直到把每一层都搜完或者找到KV。
Put时与LSM-tree中一样,但在Compaction时,先将第i层的Guard中的SSTable进行Merge,然后按照插入KV对时插入的Guard和以前就在i+1层存在的Guard,把Merge后的结果分开,写入下一层。这个过程没有读取下一层的KV数据,直接把上一层的写入下一层。
注意这里不会随着写的越多,下层Guard里面的数据越来越碎片化,一个Guard里面的SSTable越来越多,因为插入KV对时有概率插入一个Guard,插入的Guard在Compaction到下一层的时候会正式投入使用,也就是说,一个Guard内的SSTable的数量大概是一致的,但越往下层走,Guard的数量越多,这种结构也就类似于跳表的样式。
RangeQuery的时候,首先在每一层中二分搜索到范围对应的那些Guard,然后在这些Guard里的每个SSTable中Seek(key1),找到大于等于key1的最小Key。接着在这些SSTable的Seek结果中Merge,这时一层的Query结果就有了。最后将每一层的结果再做一次Merge,返回结果给用户。
ADOC
Write-Stall现象
虽然基于LSM的KV系统可以提供更高的吞吐,但是当这些系统面临高写入压力的负载时,会频繁的出现write-stall现象。
写停顿现象有两个特征:
- 从HDD到PM持久内存,写停顿发生在各种类型的设备上。
- 写停顿是设备依赖的,写停顿的持续时间和性能下降率由设备类型和写入密度等因素决定。
论文提出了Automatic Data Overflow Control ADOC,通过协调LSM-KV系统各个组件之间的数据流动来减少写停顿。
先前的bLSM、SILK等在特定的配置上减小写停顿,分析难以一般化。还有一些研究将写停顿归于资源耗尽,但可以发现写停顿在硬件资源充足的情况下也会发生。这就表明写停顿不仅发生在被动阻塞,当KV系统尝试避免更进一步的性能损失时,也会主动停顿。比如LevelDB和RocksDB为避免Disk Overflow,使用的主动停顿策略,Disk Overflow是指当flush或者compaction的作业跟不上写入速率的情况。
写停顿的原因应是Disk Overflow 的泛化,称为data overflow,是指LSM-KV系统的一个或者多个组件因为流向某个组件的数据流激增而迅速膨胀。
论文把data overflow根据形成原因分成三种: 1.
其他相关主题的待读论文
ASPLOS 2020
Hailstorm: Disaggregated Compute and Storage for Distributed LSM-based Databases
论文doi: https://doi.org/10.1145/3373376.3378504
Abstract: Distributed LSM-based databases face throughput and latency issues due to load imbalance across instances and interference from background tasks such as flushing, compaction, and data migration. Hailstorm addresses these problems by deploying the database storage engines over a distributed filesystem that disaggregates storage from processing, enabling storage pooling and compaction offloading. Hailstorm pools storage devices within a rack, allowing each storage engine to fully utilize the aggregate rack storage capacity and bandwidth. Storage pooling successfully handles load imbalance without the need for resharding. Hailstorm offloads compaction tasks to remote nodes, distributing their impact, and improving overall system throughput and response time. We show that Hailstorm achieves load balance in many MongoDB deployments with skewed workloads, improving the average throughput by 60%, while decreasing tail latency by as much as 5×. In workloads with range queries, Hailstorm provides up to 22× throughput improvements. Hailstorm also enables cost savings of 47-56% in OLTP workloads.
ASPLOS 2023
Revisiting Log-Structured Merging for KV Stores in Hybrid Memory Systems
论文doi: https://doi.org/10.1145/3575693.3575715
Abstract: We present MioDB, a novel LSM-tree based key-value (KV) store system designed to fully exploit the advantages of byte-addressable non-volatile memories (NVMs).
Our experimental studies reveal that the performance bottleneck of LSM-tree based KV stores using NVMs mainly stems from (1) costly data serialization/deserialization across memory and storage, and
(2) unbalanced speed between memory-to-disk data flushing and on-disk data compaction. They may cause unpredictable performance degradation due to write stalls and write amplification. To address these problems, we advocate byte-addressable and persistent skip lists to replace the on-disk data structure of LSM-tree, and design four novel techniques to make the best use of fast NVMs. First, we propose one-piece flushing to minimize the cost of data serialization from DRAM to NVM. Second, we exploit an elastic NVM buffer with multiple levels and zero-copy compaction to eliminate write stalls and reduce write amplification. Third, we propose parallel compaction to orchestrate data flushing and compactions across all levels of LSM-trees. Finally, MioDB increases the depth of LSM-tree and exploits bloom filters to improve the read performance. Our extensive experimental studies demonstrate that MioDB achieves 17.1× and 21.7× lower 99.9th percentile latency, 8.3× and 2.5× higher random write throughput, and up to 5× and 4.9× lower write amplification compared with the state-of-the-art NoveLSM and MatrixKV, respectively.
EuroSys 2022
p2KVS: a portable 2-dimensional parallelizing framework to improve scalability of key-value stores on SSDs
论文doi: https://doi.org/10.1145/3492321.3519567
Abstract: Attempts to improve the performance of key-value stores (KVS) by replacing the slow Hard Disk Drives (HDDs) with much faster Solid-State Drives (SSDs) have consistently fallen short of the performance gains implied by the large speed gap between SSDs and HDDs, especially for small KV items. We experimentally and holistically explore the root causes of performance inefficiency of existing LSM-tree based KVSs running on powerful modern hardware with multicore processors and fast SSDs. Our findings reveal that the global write-ahead-logging (WAL) and index-updating (MemTable) can become bottlenecks that are as fundamental and severe as the commonly known LSM-tree compaction bottleneck, under both the single-threaded and multi-threaded execution environments.
To fully exploit the performance potentials of full-fledged KVS and the underlying high-performance hardware, we propose a portable 2-dimensional KVS parallelizing framework, referred to as p2KVS. In the horizontal inter-KVS-instance dimension, p2KVS partitions a global KV space into a set of independent subspaces, each of which is maintained by an LSM-tree instance and a dedicated worker thread pinned to a dedicated core, thus eliminating structural competition on shared data structures. In the vertical intra-KVS-instancedimension, p2KVS separates user threads from KVS-workers and presents a runtime queue-based opportunistic batch mechanism on each worker, thus boosting process efficiency. Since p2KVS is designed and implemented as a user-space request scheduler, viewing WAL, MemTables, and LSM-trees as black boxes, it is nonintrusive and highly portable. Under micro and macro-benchmarks, p2KVS is shown to gain up to 4.6× write and 5.4× read speedups over the state-of-the-art RocksDB.
Tebis: index shipping for efficient replication in LSM key-value stores
论文doi: https://doi.org/10.1145/3492321.3519572
Abstract: Key-value (KV) stores based on LSM tree have become a foundational layer in the storage stack of datacenters and cloud services. Current approaches for achieving reliability and availability favor reducing network traffic and send to replicas only new KV pairs. As a result, they perform costly compactions to reorganize data in both the primary and backup nodes, which increases device I/O traffic and CPU overhead, and eventually hurts overall system performance. In this paper we describe Tebis, an efficient LSM-based KV store that reduces I/O amplification and CPU overhead for maintaining the replica index. We use a primary-backup replication scheme that performs compactions only on the primary nodes and sends pre-built indexes to backup nodes, avoiding all compactions in backup nodes. Our approach includes an efficient mechanism to deal with pointer translation across nodes in the pre-built region index. Our results show that Tebis reduces pressure on backup nodes compared to performing full compactions: Throughput is increased by 1.1 -- 1.48×, CPU efficiency is increased by 1.06 -- 1.54×, and I/O amplification is reduced by 1.13 -- 1.81×, without increasing server to server network traffic excessively (by up to 1.09 -- 1.82×).
EuroSys 2023
All-Flash Array Key-Value Cache for Large Objects
论文doi: https://doi.org/10.1145/3552326.3567509
Abstract: We present BigKV, a key-value cache specifically designed for caching large objects in an all-flash array (AFA). The design of BigKV is centered around the unique property of a cache: since it contains a copy of the data, exact bookkeeping of what is in the cache is not critical for correctness. By ignoring hash collisions, approximating metadata information, and allowing data loss from failures, BigKV significantly increases the cache hit ratio and keeps more useful objects in the system. Experiments on a real AFA show that our design increases the throughput by 3.1× on average and reduces the average and tail latency by 57% and 81%, respectively.
FlowKV: A Semantic-Aware Store for Large-Scale State Management of Stream Processing Engines
论文doi: https://doi.org/10.1145/3552326.3567493
Abstract: We propose FlowKV, a persistent store tailored for large-scale state management of streaming applications. Unlike existing KV stores, FlowKV leverages information from stream processing engines by taking a principled approach toward exploiting information about how and when the applications access data. FlowKV categorizes data access patterns of window operations according to how window boundaries are set and how tuples inside a window are aggregated, and deploys customized in-memory and on-disk data structures optimized for each pattern. In addition, FlowKV takes window metadata as explicit arguments of read and write methods to predict the moment when a window is read, and then loads the tuples of windows in batches from storage ahead of time. Using the NEXMark benchmark as workload, our experiments show that Apache Flink on FlowKV outperforms Flink on RocksDB or Faster with up to 4.12× throughput gain.
FAST2022
Closing the B+-tree vs. LSM-tree Write Amplification Gap on Modern Storage Hardware with Built-in Transparent Compression
Abstract: This paper studies how B+-tree could take full advantage of modern storage hardware with built-in transparent compression. Recent years witnessed significant interest in applying log-structured merge tree (LSM-tree) as an alternative to B+-tree, driven by the widely accepted belief that LSM-tree has distinct advantages in terms of storage cost and write amplification. This paper aims to revisit this belief upon the arrival of storage hardware with built-in transparent compression. Advanced storage appliances and emerging computational storage drives perform hardware-based lossless data compression, transparent to OS and user applications. Beyond straightforwardly reducing the storage cost gap between B+-tree and LSM-tree, such storage hardware creates new opportunities to re-think the implementation of B+-tree. This paper presents three simple design techniques that can leverage such modern storage hardware to significantly reduce the B+-tree write amplification. Experiments on a commercial storage drive with built-in transparent compression show that the proposed design techniques can reduce the B+-tree write amplification by over 10× . Compared with RocksDB (a key-value store built upon LSM-tree), the enhanced B+-tree implementation can achieve similar or even smaller write amplification.
Removing Double-Logging with Passive Data Persistence in LSM-tree based Relational Databases
Abstract: Storage engine is a crucial component in relational databases (RDBs). With the emergence of Internet services and applications, a recent technical trend is to deploy a Log-structured Merge Tree (LSM-tree) based storage engine. Although such an approach can achieve high performance and efficient storage space usage, it also brings a critical double-logging problem——In LSM-tree based RDBs, both the upper RDB layer and the lower storage engine layer implement redundant logging facilities, which perform synchronous and costly I/Os for data persistence. Unfortunately, such “double protection” does not provide extra benefits but only incurs heavy and unnecessary performance overhead.
In this paper, we propose a novel solution, called Passive Data Persistence Scheme (PASV), to address the double-logging problem in LSM-tree based RDBs. By completely removing Write-ahead Log (WAL) in the storage engine layer, we develop a set of mechanisms, including a passive memory buffer flushing policy, an epoch-based data persistence scheme, and an optimized partial data recovery process, to achieve reliable and low-cost data persistence during normal runs and also fast and efficient recovery upon system failures. We implement a fully functional, open-sourced prototype of PASV based on Facebook’s MyRocks. Evaluation results show that our solution can effectively improve system performance by increasing throughput by up to 49.9% and reducing latency by up to 89.3%, and it also saves disk I/Os by up to 42.9% and reduces recovery time by up to 4.8%.
Overview
Overview
Others
Methods of doing systems research and writing papers
https://i.cs.hku.hk/~heming/misc/methods.html
You and Your Rearch
Chinese
https://www.ruanyifeng.com/blog/2016/04/you-and-your-research.html
English
https://www.cs.virginia.edu/~robins/YouAndYourResearch.html
华科高性能体系结构与系统实验室
科研指南
https://haslab.org/docs/research/index.html
VIM GOLF
ganesha内存盘 libaio ##X86 2 [root@node-191 ~]# ./stream
STREAM version $Revision: 5.10 $
This system uses 8 bytes per array element.
***** WARNING: ****** It appears that you set the preprocessor variable N when compiling this code. This version of the code uses the preprocesor variable STREAM_ARRAY_SIZE to control the array size Reverting to default value of STREAM_ARRAY_SIZE=10000000 ***** WARNING: ****** Array size = 10000000 (elements), Offset = 0 (elements) Memory per array = 76.3 MiB (= 0.1 GiB). Total memory required = 228.9 MiB (= 0.2 GiB). Each kernel will be executed 10 times. The best time for each kernel (excluding the first iteration) will be used to compute the reported bandwidth.
Number of Threads requested = 56 Number of Threads counted = 56
Your clock granularity/precision appears to be 1 microseconds. Each test below will take on the order of 3473 microseconds. (= 3473 clock ticks) Increase the size of the arrays if this shows that you are not getting at least 20 clock ticks per test.
WARNING -- The above is only a rough guideline. For best results, please be sure you know the precision of your system timer.
Function Best Rate MB/s Avg time Min time Max time Copy: 77519.8 0.002207 0.002064 0.002785 Scale: 67425.8 0.002690 0.002373 0.003889 Add: 70670.7 0.003597 0.003396 0.003898 Triad: 74049.8 0.003420 0.003241 0.003723
Solution Validates: avg error less than 1.000000e-13 on all three arrays
[root@ceph192 ~]# ./stream
STREAM version $Revision: 5.10 $
This system uses 8 bytes per array element.
***** WARNING: ****** It appears that you set the preprocessor variable N when compiling this code. This version of the code uses the preprocesor variable STREAM_ARRAY_SIZE to control the array size Reverting to default value of STREAM_ARRAY_SIZE=10000000 ***** WARNING: ****** Array size = 10000000 (elements), Offset = 0 (elements) Memory per array = 76.3 MiB (= 0.1 GiB). Total memory required = 228.9 MiB (= 0.2 GiB). Each kernel will be executed 10 times. The best time for each kernel (excluding the first iteration) will be used to compute the reported bandwidth.
Number of Threads requested = 16 Number of Threads counted = 16
Your clock granularity/precision appears to be 1 microseconds. Each test below will take on the order of 4297 microseconds. (= 4297 clock ticks) Increase the size of the arrays if this shows that you are not getting at least 20 clock ticks per test.
WARNING -- The above is only a rough guideline. For best results, please be sure you know the precision of your system timer.
Function Best Rate MB/s Avg time Min time Max time Copy: 35964.0 0.004598 0.004449 0.004810 Scale: 37985.4 0.004316 0.004212 0.004794 Add: 30766.0 0.007990 0.007801 0.008304 Triad: 38308.5 0.006377 0.006265 0.006529
Solution Validates: avg error less than 1.000000e-13 on all three arrays
16k
##16k Seq写测试 fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file16kwrite_seq
LA
[root@ceph192 mnt]# fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=write, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 7 (f=7): [W(6),(2),W(1),(1)][94.3%][w=400MiB/s][w=25.6k IOPS][eta 00m:03Jobs: 3 (f=3): [(4),W(2),(2),W(1),_(1)][96.2%][w=350MiB/s][w=22.4k IOPS][eta 00m:02s] file16kwrite_seq: (groupid=0, jobs=10): err= 0: pid=50533: Thu Aug 31 03:07:39 2023 write: IOPS=25.4k, BW=397MiB/s (416MB/s)(20.0GiB/51617msec); 0 zone resets clat (usec): min=105, max=5320, avg=381.05, stdev=93.92 lat (usec): min=105, max=5321, avg=381.80, stdev=93.93 clat percentiles (usec): | 1.00th=[ 176], 5.00th=[ 245], 10.00th=[ 281], 20.00th=[ 314], | 30.00th=[ 338], 40.00th=[ 359], 50.00th=[ 375], 60.00th=[ 396], | 70.00th=[ 416], 80.00th=[ 445], 90.00th=[ 486], 95.00th=[ 529], | 99.00th=[ 619], 99.50th=[ 652], 99.90th=[ 807], 99.95th=[ 1156], | 99.99th=[ 2278] bw ( KiB/s): min=388512, max=564103, per=100.00%, avg=413969.89, stdev=2435.10, samples=1004 iops : min=24282, max=35256, avg=25873.07, stdev=152.17, samples=1004 lat (usec) : 250=5.55%, 500=86.41%, 750=7.90%, 1000=0.08% lat (msec) : 2=0.04%, 4=0.02%, 10=0.01% cpu : usr=0.95%, sys=2.75%, ctx=1327195, majf=0, minf=0 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,1310720,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=397MiB/s (416MB/s), 397MiB/s-397MiB/s (416MB/s-416MB/s), io=20.0GiB (21.5GB), run=51617-51617msec
X86 1
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=file16kwrite_rand file16kwrite_rand: (g=0): rw=write, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=1 ... fio-3.33 Starting 10 threads Jobs: 10 (f=10): [W(10)][100.0%][w=16.6MiB/s][w=1065 IOPS][eta 00m:00s] file16kwrite_rand: (groupid=0, jobs=10): err= 0: pid=18704: Thu Aug 31 15:07:40 2023 write: IOPS=1052, BW=16.5MiB/s (17.3MB/s)(987MiB/60005msec); 0 zone resets clat (usec): min=4539, max=26747, avg=9482.53, stdev=1710.02 lat (usec): min=4539, max=26749, avg=9483.64, stdev=1710.02 clat percentiles (usec): | 1.00th=[ 6390], 5.00th=[ 7177], 10.00th=[ 7635], 20.00th=[ 8160], | 30.00th=[ 8586], 40.00th=[ 8979], 50.00th=[ 9241], 60.00th=[ 9634], | 70.00th=[10028], 80.00th=[10552], 90.00th=[11600], 95.00th=[12649], | 99.00th=[15139], 99.50th=[16188], 99.90th=[18482], 99.95th=[20055], | 99.99th=[22152] bw ( KiB/s): min=14912, max=18048, per=100.00%, avg=16856.47, stdev=47.15, samples=1190 iops : min= 932, max= 1128, avg=1053.53, stdev= 2.95, samples=1190 lat (msec) : 10=69.59%, 20=30.36%, 50=0.05% cpu : usr=0.14%, sys=0.43%, ctx=63247, majf=0, minf=0 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,63185,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=16.5MiB/s (17.3MB/s), 16.5MiB/s-16.5MiB/s (17.3MB/s-17.3MB/s), io=987MiB (1035MB), run=60005-60005msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=write, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [W(10)][100.0%][w=871MiB/s][w=55.7k IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=10): err= 0: pid=2744788: Fri Sep 1 04:01:11 2023 write: IOPS=55.5k, BW=866MiB/s (909MB/s)(20.0GiB/23636msec); 0 zone resets clat (usec): min=59, max=687, avg=179.59, stdev=33.09 lat (usec): min=60, max=687, avg=179.84, stdev=33.09 clat percentiles (usec): | 1.00th=[ 127], 5.00th=[ 143], 10.00th=[ 149], 20.00th=[ 159], | 30.00th=[ 165], 40.00th=[ 169], 50.00th=[ 176], 60.00th=[ 180], | 70.00th=[ 186], 80.00th=[ 196], 90.00th=[ 212], 95.00th=[ 237], | 99.00th=[ 310], 99.50th=[ 347], 99.90th=[ 433], 99.95th=[ 465], | 99.99th=[ 529] bw ( KiB/s): min=847872, max=915232, per=100.00%, avg=888209.02, stdev=1376.49, samples=470 iops : min=52992, max=57202, avg=55513.06, stdev=86.03, samples=470 lat (usec) : 100=0.06%, 250=96.34%, 500=3.58%, 750=0.02% cpu : usr=0.95%, sys=3.37%, ctx=1310781, majf=0, minf=1 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,1310720,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=866MiB/s (909MB/s), 866MiB/s-866MiB/s (909MB/s-909MB/s), io=20.0GiB (21.5GB), run=23636-23636msec
16k Rand写测试
fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file16kwrite_rand
LA
[root@ceph192 mnt]# fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file16kwrite_rand file16kwrite_rand: (g=0): rw=randwrite, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 7 (f=7): [w(4),(2),w(2),(1),w(1)][96.1%][w=407MiB/s][w=26.1k IOPS][eta 0Jobs: 1 (f=1): [_(9),w(1)][100.0%][w=266MiB/s][w=17.0k IOPS][eta 00m:00s] file16kwrite_rand: (groupid=0, jobs=10): err= 0: pid=50596: Thu Aug 31 03:10:49 2023 write: IOPS=26.2k, BW=409MiB/s (429MB/s)(20.0GiB/50027msec); 0 zone resets clat (usec): min=109, max=2751, avg=369.77, stdev=78.95 lat (usec): min=110, max=2752, avg=370.51, stdev=78.96 clat percentiles (usec): | 1.00th=[ 192], 5.00th=[ 253], 10.00th=[ 281], 20.00th=[ 314], | 30.00th=[ 334], 40.00th=[ 351], 50.00th=[ 367], 60.00th=[ 383], | 70.00th=[ 400], 80.00th=[ 424], 90.00th=[ 457], 95.00th=[ 494], | 99.00th=[ 578], 99.50th=[ 627], 99.90th=[ 766], 99.95th=[ 881], | 99.99th=[ 2114] bw ( KiB/s): min=399456, max=570432, per=100.00%, avg=426501.75, stdev=2107.36, samples=974 iops : min=24966, max=35652, avg=26656.38, stdev=131.71, samples=974 lat (usec) : 250=4.65%, 500=91.08%, 750=4.16%, 1000=0.08% lat (msec) : 2=0.02%, 4=0.01% cpu : usr=1.13%, sys=2.86%, ctx=1310998, majf=0, minf=0 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,1310720,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=409MiB/s (429MB/s), 409MiB/s-409MiB/s (429MB/s-429MB/s), io=20.0GiB (21.5GB), run=50027-50027msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=file16kwrite_rand file16kwrite_rand: (g=0): rw=randwrite, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=1 ... fio-3.33 Starting 10 threads Jobs: 10 (f=10): [w(10)][100.0%][w=16.2MiB/s][w=1039 IOPS][eta 00m:00s] file16kwrite_rand: (groupid=0, jobs=10): err= 0: pid=18790: Thu Aug 31 15:10:46 2023 write: IOPS=1124, BW=17.6MiB/s (18.4MB/s)(1054MiB/60005msec); 0 zone resets clat (usec): min=3851, max=56140, avg=8884.05, stdev=1771.57 lat (usec): min=3852, max=56142, avg=8885.16, stdev=1771.57 clat percentiles (usec): | 1.00th=[ 5473], 5.00th=[ 6521], 10.00th=[ 6980], 20.00th=[ 7570], | 30.00th=[ 8029], 40.00th=[ 8356], 50.00th=[ 8717], 60.00th=[ 9110], | 70.00th=[ 9503], 80.00th=[10028], 90.00th=[10945], 95.00th=[11863], | 99.00th=[14353], 99.50th=[15270], 99.90th=[17695], 99.95th=[19268], | 99.99th=[53740] bw ( KiB/s): min=15264, max=25024, per=100.00%, avg=18006.05, stdev=128.67, samples=1190 iops : min= 954, max= 1564, avg=1125.38, stdev= 8.04, samples=1190 lat (msec) : 4=0.01%, 10=79.93%, 20=20.02%, 50=0.03%, 100=0.01% cpu : usr=0.16%, sys=0.47%, ctx=67536, majf=0, minf=0 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,67450,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=17.6MiB/s (18.4MB/s), 17.6MiB/s-17.6MiB/s (18.4MB/s-18.4MB/s), io=1054MiB (1105MB), run=60005-60005msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file16kwrite_rand file16kwrite_rand: (g=0): rw=randwrite, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [w(10)][100.0%][w=872MiB/s][w=55.8k IOPS][eta 00m:00s] file16kwrite_rand: (groupid=0, jobs=10): err= 0: pid=2744893: Fri Sep 1 04:02:04 2023 write: IOPS=55.3k, BW=865MiB/s (907MB/s)(20.0GiB/23682msec); 0 zone resets clat (usec): min=63, max=742, avg=179.81, stdev=33.14 lat (usec): min=64, max=743, avg=180.06, stdev=33.15 clat percentiles (usec): | 1.00th=[ 127], 5.00th=[ 143], 10.00th=[ 151], 20.00th=[ 159], | 30.00th=[ 165], 40.00th=[ 169], 50.00th=[ 176], 60.00th=[ 180], | 70.00th=[ 188], 80.00th=[ 196], 90.00th=[ 212], 95.00th=[ 237], | 99.00th=[ 306], 99.50th=[ 347], 99.90th=[ 445], 99.95th=[ 474], | 99.99th=[ 537] bw ( KiB/s): min=853824, max=914720, per=100.00%, avg=886436.77, stdev=1343.79, samples=470 iops : min=53364, max=57170, avg=55402.26, stdev=83.99, samples=470 lat (usec) : 100=0.05%, 250=96.44%, 500=3.48%, 750=0.03% cpu : usr=1.00%, sys=3.40%, ctx=1310768, majf=0, minf=1 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,1310720,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=865MiB/s (907MB/s), 865MiB/s-865MiB/s (907MB/s-907MB/s), io=20.0GiB (21.5GB), run=23682-23682msec
16k Seq读测试
fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file16kread_seq
LA
[root@ceph192 mnt]# fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file16kread_seq file16kread_seq: (g=0): rw=read, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 1 (f=1): [(7),R(1),(2)][100.0%][r=267MiB/s][r=17.1k IOPS][eta 00m:00s] file16kread_seq: (groupid=0, jobs=10): err= 0: pid=50648: Thu Aug 31 03:13:08 2023 read: IOPS=27.3k, BW=427MiB/s (448MB/s)(20.0GiB/47935msec) clat (usec): min=96, max=5412, avg=354.63, stdev=91.13 lat (usec): min=96, max=5413, avg=355.14, stdev=91.14 clat percentiles (usec): | 1.00th=[ 169], 5.00th=[ 231], 10.00th=[ 258], 20.00th=[ 289], | 30.00th=[ 310], 40.00th=[ 330], 50.00th=[ 347], 60.00th=[ 367], | 70.00th=[ 392], 80.00th=[ 416], 90.00th=[ 461], 95.00th=[ 502], | 99.00th=[ 586], 99.50th=[ 627], 99.90th=[ 783], 99.95th=[ 1139], | 99.99th=[ 2147] bw ( KiB/s): min=412864, max=621707, per=100.00%, avg=445635.61, stdev=3256.56, samples=933 iops : min=25804, max=38855, avg=27852.21, stdev=203.50, samples=933 lat (usec) : 100=0.01%, 250=8.49%, 500=86.48%, 750=4.91%, 1000=0.06% lat (msec) : 2=0.04%, 4=0.02%, 10=0.01% cpu : usr=0.74%, sys=2.96%, ctx=1319816, majf=0, minf=10 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=1310720,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=427MiB/s (448MB/s), 427MiB/s-427MiB/s (448MB/s-448MB/s), io=20.0GiB (21.5GB), run=47935-47935msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=file16kread_seq file16kread_seq: (g=0): rw=read, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=1 ... fio-3.33 Starting 10 threads Jobs: 10 (f=10): [R(10)][100.0%][r=14.8MiB/s][r=949 IOPS][eta 00m:00s] file16kread_seq: (groupid=0, jobs=10): err= 0: pid=19246: Thu Aug 31 15:19:26 2023 read: IOPS=985, BW=15.4MiB/s (16.1MB/s)(924MiB/60005msec) clat (usec): min=5132, max=86115, avg=10138.65, stdev=1518.30 lat (usec): min=5132, max=86116, avg=10139.35, stdev=1518.31 clat percentiles (usec): | 1.00th=[ 7373], 5.00th=[ 8356], 10.00th=[ 8848], 20.00th=[ 9241], | 30.00th=[ 9634], 40.00th=[ 9896], 50.00th=[10159], 60.00th=[10290], | 70.00th=[10552], 80.00th=[10945], 90.00th=[11469], 95.00th=[11994], | 99.00th=[13304], 99.50th=[13960], 99.90th=[16319], 99.95th=[19268], | 99.99th=[85459] bw ( KiB/s): min=13312, max=18208, per=100.00%, avg=15774.52, stdev=73.14, samples=1190 iops : min= 832, max= 1138, avg=985.90, stdev= 4.57, samples=1190 lat (msec) : 10=45.66%, 20=54.30%, 50=0.03%, 100=0.02% cpu : usr=0.11%, sys=0.38%, ctx=59155, majf=0, minf=40 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=59105,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=15.4MiB/s (16.1MB/s), 15.4MiB/s-15.4MiB/s (16.1MB/s-16.1MB/s), io=924MiB (968MB), run=60005-60005msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file16kread_seq file16kread_seq: (g=0): rw=read, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [R(10)][100.0%][r=878MiB/s][r=56.2k IOPS][eta 00m:00s] file16kread_seq: (groupid=0, jobs=10): err= 0: pid=2744967: Fri Sep 1 04:02:52 2023 read: IOPS=56.8k, BW=887MiB/s (930MB/s)(20.0GiB/23082msec) clat (usec): min=55, max=696, avg=175.57, stdev=30.35 lat (usec): min=55, max=696, avg=175.63, stdev=30.35 clat percentiles (usec): | 1.00th=[ 129], 5.00th=[ 143], 10.00th=[ 149], 20.00th=[ 155], | 30.00th=[ 161], 40.00th=[ 165], 50.00th=[ 169], 60.00th=[ 176], | 70.00th=[ 182], 80.00th=[ 190], 90.00th=[ 208], 95.00th=[ 233], | 99.00th=[ 293], 99.50th=[ 310], 99.90th=[ 359], 99.95th=[ 379], | 99.99th=[ 449] bw ( KiB/s): min=863584, max=940320, per=100.00%, avg=909645.91, stdev=1909.57, samples=460 iops : min=53974, max=58770, avg=56852.87, stdev=119.35, samples=460 lat (usec) : 100=0.03%, 250=96.61%, 500=3.36%, 750=0.01% cpu : usr=0.75%, sys=3.49%, ctx=1310763, majf=0, minf=41 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=1310720,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=887MiB/s (930MB/s), 887MiB/s-887MiB/s (930MB/s-930MB/s), io=20.0GiB (21.5GB), run=23082-23082msec
16k Rand读测试
fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file16kread_rand
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file16kread_rand file16kread_rand: (g=0): rw=randread, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 2 (f=2): [r(1),(6),r(1),(2)][97.9%][r=438MiB/s][r=28.0k IOPS][eta 00m:01s] file16kread_rand: (groupid=0, jobs=10): err= 0: pid=50814: Thu Aug 31 03:23:05 2023 read: IOPS=28.8k, BW=450MiB/s (472MB/s)(20.0GiB/45508msec) clat (usec): min=102, max=2510, avg=337.28, stdev=79.92 lat (usec): min=103, max=2510, avg=337.85, stdev=79.94 clat percentiles (usec): | 1.00th=[ 178], 5.00th=[ 229], 10.00th=[ 253], 20.00th=[ 281], | 30.00th=[ 302], 40.00th=[ 314], 50.00th=[ 330], 60.00th=[ 347], | 70.00th=[ 367], 80.00th=[ 392], 90.00th=[ 429], 95.00th=[ 461], | 99.00th=[ 537], 99.50th=[ 570], 99.90th=[ 709], 99.95th=[ 1090], | 99.99th=[ 2212] bw ( KiB/s): min=433902, max=581343, per=100.00%, avg=466946.77, stdev=2252.79, samples=890 iops : min=27114, max=36333, avg=29184.12, stdev=140.79, samples=890 lat (usec) : 250=9.20%, 500=88.63%, 750=2.09%, 1000=0.03% lat (msec) : 2=0.03%, 4=0.02% cpu : usr=0.87%, sys=3.29%, ctx=1396628, majf=0, minf=10 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=1310720,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=450MiB/s (472MB/s), 450MiB/s-450MiB/s (472MB/s-472MB/s), io=20.0GiB (21.5GB), run=45508-45508msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=file16kread_rand file16kread_rand: (g=0): rw=randread, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=1 ... fio-3.33 Starting 10 threads Jobs: 10 (f=10): [r(10)][100.0%][r=15.8MiB/s][r=1012 IOPS][eta 00m:00s] file16kread_rand: (groupid=0, jobs=10): err= 0: pid=19490: Thu Aug 31 15:23:24 2023 read: IOPS=1032, BW=16.1MiB/s (16.9MB/s)(968MiB/60004msec) clat (usec): min=4412, max=42299, avg=9670.80, stdev=1362.93 lat (usec): min=4413, max=42299, avg=9671.53, stdev=1362.93 clat percentiles (usec): | 1.00th=[ 6063], 5.00th=[ 7504], 10.00th=[ 8094], 20.00th=[ 8717], | 30.00th=[ 9110], 40.00th=[ 9372], 50.00th=[ 9765], 60.00th=[10028], | 70.00th=[10290], 80.00th=[10683], 90.00th=[11207], 95.00th=[11600], | 99.00th=[12911], 99.50th=[13566], 99.90th=[15795], 99.95th=[16909], | 99.99th=[39584] bw ( KiB/s): min=13856, max=22816, per=100.00%, avg=16529.75, stdev=129.98, samples=1190 iops : min= 866, max= 1426, avg=1033.11, stdev= 8.12, samples=1190 lat (msec) : 10=59.95%, 20=40.04%, 50=0.02% cpu : usr=0.12%, sys=0.41%, ctx=61992, majf=0, minf=40 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=61956,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=16.1MiB/s (16.9MB/s), 16.1MiB/s-16.1MiB/s (16.9MB/s-16.9MB/s), io=968MiB (1015MB), run=60004-60004msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/16k -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=16k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file16kread_rand file16kread_rand: (g=0): rw=randread, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [r(10)][100.0%][r=870MiB/s][r=55.7k IOPS][eta 00m:00s] file16kread_rand: (groupid=0, jobs=10): err= 0: pid=2745284: Fri Sep 1 04:10:25 2023 read: IOPS=56.6k, BW=884MiB/s (927MB/s)(20.0GiB/23172msec) clat (usec): min=54, max=643, avg=176.13, stdev=28.80 lat (usec): min=54, max=643, avg=176.20, stdev=28.80 clat percentiles (usec): | 1.00th=[ 129], 5.00th=[ 143], 10.00th=[ 149], 20.00th=[ 157], | 30.00th=[ 163], 40.00th=[ 167], 50.00th=[ 172], 60.00th=[ 178], | 70.00th=[ 182], 80.00th=[ 192], 90.00th=[ 206], 95.00th=[ 227], | 99.00th=[ 293], 99.50th=[ 310], 99.90th=[ 359], 99.95th=[ 379], | 99.99th=[ 433] bw ( KiB/s): min=862208, max=940480, per=100.00%, avg=905840.15, stdev=1534.39, samples=460 iops : min=53888, max=58780, avg=56614.96, stdev=95.90, samples=460 lat (usec) : 100=0.03%, 250=97.22%, 500=2.75%, 750=0.01% cpu : usr=0.85%, sys=3.42%, ctx=1310767, majf=0, minf=41 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=1310720,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=884MiB/s (927MB/s), 884MiB/s-884MiB/s (927MB/s-927MB/s), io=20.0GiB (21.5GB), run=23172-23172msec
64k
64k Seq写测试
fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file64kwrite_seq
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file64kwrite_seq file64kwrite_seq: (g=0): rw=write, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads file64kwrite_seq: Laying out IO file (1 file / 2048MiB) Jobs: 9 (f=9): [W(8),_(1),W(1)][95.0%][w=1104MiB/s][w=17.7k IOPS][eta 00m:01s] file64kwrite_seq: (groupid=0, jobs=10): err= 0: pid=50870: Thu Aug 31 03:24:23 2023 write: IOPS=17.6k, BW=1101MiB/s (1154MB/s)(20.0GiB/18608msec); 0 zone resets clat (usec): min=160, max=4740, avg=554.37, stdev=121.13 lat (usec): min=162, max=4741, avg=555.81, stdev=121.13 clat percentiles (usec): | 1.00th=[ 269], 5.00th=[ 359], 10.00th=[ 408], 20.00th=[ 469], | 30.00th=[ 502], 40.00th=[ 529], 50.00th=[ 562], 60.00th=[ 586], | 70.00th=[ 611], 80.00th=[ 644], 90.00th=[ 693], 95.00th=[ 734], | 99.00th=[ 824], 99.50th=[ 865], 99.90th=[ 1123], 99.95th=[ 1876], | 99.99th=[ 2507] bw ( MiB/s): min= 1079, max= 1137, per=100.00%, avg=1109.57, stdev= 1.49, samples=358 iops : min=17270, max=18206, avg=17752.92, stdev=23.86, samples=358 lat (usec) : 250=0.64%, 500=28.24%, 750=67.33%, 1000=3.66% lat (msec) : 2=0.09%, 4=0.04%, 10=0.01% cpu : usr=0.95%, sys=2.35%, ctx=337781, majf=0, minf=0 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,327680,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=1101MiB/s (1154MB/s), 1101MiB/s-1101MiB/s (1154MB/s-1154MB/s), io=20.0GiB (21.5GB), run=18608-18608msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=file64kwrite_seq file64kwrite_seq: (g=0): rw=write, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=psync, iodepth=1 ... fio-3.33 Starting 10 threads file64kwrite_seq: Laying out IO file (1 file / 2048MiB) Jobs: 10 (f=10): [W(10)][100.0%][w=64.8MiB/s][w=1036 IOPS][eta 00m:00s] file64kwrite_seq: (groupid=0, jobs=10): err= 0: pid=19598: Thu Aug 31 15:25:08 2023 write: IOPS=1048, BW=65.5MiB/s (68.7MB/s)(3932MiB/60007msec); 0 zone resets clat (usec): min=3606, max=26680, avg=9524.68, stdev=1720.54 lat (usec): min=3608, max=26683, avg=9527.44, stdev=1720.53 clat percentiles (usec): | 1.00th=[ 6456], 5.00th=[ 7177], 10.00th=[ 7635], 20.00th=[ 8225], | 30.00th=[ 8586], 40.00th=[ 8979], 50.00th=[ 9372], 60.00th=[ 9634], | 70.00th=[10028], 80.00th=[10552], 90.00th=[11600], 95.00th=[12649], | 99.00th=[15401], 99.50th=[16450], 99.90th=[18744], 99.95th=[20055], | 99.99th=[22152] bw ( KiB/s): min=62464, max=71168, per=100.00%, avg=67127.93, stdev=177.28, samples=1190 iops : min= 976, max= 1112, avg=1048.87, stdev= 2.77, samples=1190 lat (msec) : 4=0.01%, 10=69.12%, 20=30.83%, 50=0.05% cpu : usr=0.16%, sys=0.50%, ctx=62963, majf=0, minf=0 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,62905,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=65.5MiB/s (68.7MB/s), 65.5MiB/s-65.5MiB/s (68.7MB/s-68.7MB/s), io=3932MiB (4123MB), run=60007-60007msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file64kwrite_seq file64kwrite_seq: (g=0): rw=write, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads file64kwrite_seq: Laying out IO file (1 file / 2048MiB) Jobs: 10 (f=10): [W(10)][100.0%][w=2368MiB/s][w=37.9k IOPS][eta 00m:00s] file64kwrite_seq: (groupid=0, jobs=10): err= 0: pid=2745367: Fri Sep 1 04:10:50 2023 write: IOPS=38.2k, BW=2388MiB/s (2504MB/s)(20.0GiB/8576msec); 0 zone resets clat (usec): min=79, max=1248, avg=259.16, stdev=59.62 lat (usec): min=80, max=1253, avg=260.87, stdev=59.66 clat percentiles (usec): | 1.00th=[ 143], 5.00th=[ 176], 10.00th=[ 194], 20.00th=[ 212], | 30.00th=[ 227], 40.00th=[ 239], 50.00th=[ 253], 60.00th=[ 265], | 70.00th=[ 281], 80.00th=[ 302], 90.00th=[ 334], 95.00th=[ 367], | 99.00th=[ 437], 99.50th=[ 474], 99.90th=[ 570], 99.95th=[ 619], | 99.99th=[ 734] bw ( MiB/s): min= 2286, max= 2457, per=100.00%, avg=2392.35, stdev= 4.66, samples=170 iops : min=36584, max=39326, avg=38277.65, stdev=74.51, samples=170 lat (usec) : 100=0.03%, 250=48.33%, 500=51.34%, 750=0.30%, 1000=0.01% lat (msec) : 2=0.01% cpu : usr=1.26%, sys=3.59%, ctx=327729, majf=0, minf=1 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,327680,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=2388MiB/s (2504MB/s), 2388MiB/s-2388MiB/s (2504MB/s-2504MB/s), io=20.0GiB (21.5GB), run=8576-8576msec
64k Rand写测试
fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file64kwrite_rand
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file64kwrite_rand file64kwrite_rand: (g=0): rw=randwrite, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10) Jobs: 7 (f=7): [(2),w(5),(1),w(2)][100.0%][w=1066MiB/s][w=17.1k IOPS][eta 00m:00s] file64kwrite_rand: (groupid=0, jobs=10): err= 0: pid=50936: Thu Aug 31 03:26:30 2023 write: IOPS=17.1k, BW=1070MiB/s (1122MB/s)(20.0GiB/19147msec); 0 zone resets clat (usec): min=156, max=2794, avg=570.86, stdev=109.08 lat (usec): min=157, max=2795, avg=572.27, stdev=109.08 clat percentiles (usec): | 1.00th=[ 285], 5.00th=[ 400], 10.00th=[ 449], 20.00th=[ 498], | 30.00th=[ 529], 40.00th=[ 553], 50.00th=[ 570], 60.00th=[ 594], | 70.00th=[ 619], 80.00th=[ 644], 90.00th=[ 685], 95.00th=[ 734], | 99.00th=[ 824], 99.50th=[ 865], 99.90th=[ 1123], 99.95th=[ 1876], | 99.99th=[ 2474] bw ( MiB/s): min= 1058, max= 1190, per=100.00%, avg=1079.17, stdev= 3.63, samples=372 iops : min=16938, max=19044, avg=17266.75, stdev=58.01, samples=372 lat (usec) : 250=0.59%, 500=19.99%, 750=75.92%, 1000=3.37% lat (msec) : 2=0.09%, 4=0.05% cpu : usr=1.03%, sys=2.36%, ctx=330152, majf=0, minf=0 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,327680,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=1070MiB/s (1122MB/s), 1070MiB/s-1070MiB/s (1122MB/s-1122MB/s), io=20.0GiB (21.5GB), run=19147-19147msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=file64kwrite_rand file64kwrite_rand: (g=0): rw=randwrite, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=psync, iodepth=1 ... fio-3.33 Starting 10 threads Jobs: 10 (f=10): [w(10)][100.0%][w=66.4MiB/s][w=1063 IOPS][eta 00m:00s] file64kwrite_rand: (groupid=0, jobs=10): err= 0: pid=19718: Thu Aug 31 15:27:14 2023 write: IOPS=1072, BW=67.0MiB/s (70.3MB/s)(4021MiB/60005msec); 0 zone resets clat (usec): min=4085, max=77223, avg=9312.18, stdev=1834.08 lat (usec): min=4088, max=77225, avg=9314.96, stdev=1834.09 clat percentiles (usec): | 1.00th=[ 6194], 5.00th=[ 6980], 10.00th=[ 7439], 20.00th=[ 8029], | 30.00th=[ 8455], 40.00th=[ 8717], 50.00th=[ 9110], 60.00th=[ 9372], | 70.00th=[ 9896], 80.00th=[10421], 90.00th=[11338], 95.00th=[12387], | 99.00th=[15008], 99.50th=[16188], 99.90th=[20055], 99.95th=[25035], | 99.99th=[45876] bw ( KiB/s): min=56960, max=81152, per=100.00%, avg=68657.48, stdev=281.43, samples=1190 iops : min= 890, max= 1268, avg=1072.77, stdev= 4.40, samples=1190 lat (msec) : 10=73.45%, 20=26.45%, 50=0.10%, 100=0.01% cpu : usr=0.15%, sys=0.54%, ctx=64397, majf=0, minf=0 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,64329,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=67.0MiB/s (70.3MB/s), 67.0MiB/s-67.0MiB/s (70.3MB/s-70.3MB/s), io=4021MiB (4216MB), run=60005-60005msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file64kwrite_rand file64kwrite_rand: (g=0): rw=randwrite, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [w(10)][100.0%][w=2389MiB/s][w=38.2k IOPS][eta 00m:00s] file64kwrite_rand: (groupid=0, jobs=10): err= 0: pid=2745440: Fri Sep 1 04:11:12 2023 write: IOPS=38.4k, BW=2402MiB/s (2519MB/s)(20.0GiB/8525msec); 0 zone resets clat (usec): min=83, max=1032, avg=257.64, stdev=58.49 lat (usec): min=84, max=1034, avg=259.30, stdev=58.53 clat percentiles (usec): | 1.00th=[ 145], 5.00th=[ 176], 10.00th=[ 192], 20.00th=[ 212], | 30.00th=[ 227], 40.00th=[ 239], 50.00th=[ 251], 60.00th=[ 265], | 70.00th=[ 281], 80.00th=[ 297], 90.00th=[ 330], 95.00th=[ 363], | 99.00th=[ 437], 99.50th=[ 469], 99.90th=[ 562], 99.95th=[ 611], | 99.99th=[ 791] bw ( MiB/s): min= 2280, max= 2474, per=100.00%, avg=2404.72, stdev= 4.26, samples=169 iops : min=36484, max=39588, avg=38475.66, stdev=68.16, samples=169 lat (usec) : 100=0.01%, 250=49.40%, 500=50.31%, 750=0.27%, 1000=0.01% lat (msec) : 2=0.01% cpu : usr=1.36%, sys=3.56%, ctx=327702, majf=0, minf=1 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,327680,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=2402MiB/s (2519MB/s), 2402MiB/s-2402MiB/s (2519MB/s-2519MB/s), io=20.0GiB (21.5GB), run=8525-8525msec
64k Seq读测试
fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file64kread_seq
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file64kread_seq file64kread_seq: (g=0): rw=read, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [R(10)][100.0%][r=1081MiB/s][r=17.3k IOPS][eta 00m:00s] file64kread_seq: (groupid=0, jobs=10): err= 0: pid=50982: Thu Aug 31 03:28:09 2023 read: IOPS=17.9k, BW=1121MiB/s (1176MB/s)(20.0GiB/18265msec) clat (usec): min=146, max=5059, avg=550.46, stdev=117.20 lat (usec): min=146, max=5059, avg=551.09, stdev=117.19 clat percentiles (usec): | 1.00th=[ 318], 5.00th=[ 392], 10.00th=[ 424], 20.00th=[ 465], | 30.00th=[ 494], 40.00th=[ 519], 50.00th=[ 545], 60.00th=[ 570], | 70.00th=[ 594], 80.00th=[ 627], 90.00th=[ 676], 95.00th=[ 734], | 99.00th=[ 881], 99.50th=[ 955], 99.90th=[ 1172], 99.95th=[ 1909], | 99.99th=[ 2442] bw ( MiB/s): min= 1066, max= 1158, per=100.00%, avg=1125.07, stdev= 2.27, samples=360 iops : min=17064, max=18530, avg=18001.06, stdev=36.39, samples=360 lat (usec) : 250=0.37%, 500=31.82%, 750=63.77%, 1000=3.71% lat (msec) : 2=0.29%, 4=0.04%, 10=0.01% cpu : usr=0.39%, sys=2.68%, ctx=366626, majf=0, minf=40 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=327680,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=1121MiB/s (1176MB/s), 1121MiB/s-1121MiB/s (1176MB/s-1176MB/s), io=20.0GiB (21.5GB), run=18265-18265msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=file64kread_seq file64kread_seq: (g=0): rw=read, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=psync, iodepth=1 ... fio-3.33 Starting 10 threads Jobs: 10 (f=10): [R(10)][100.0%][r=58.4MiB/s][r=933 IOPS][eta 00m:00s] file64kread_seq: (groupid=0, jobs=10): err= 0: pid=19837: Thu Aug 31 15:28:55 2023 read: IOPS=970, BW=60.7MiB/s (63.6MB/s)(3640MiB/60008msec) clat (usec): min=3640, max=41188, avg=10291.90, stdev=1100.27 lat (usec): min=3641, max=41189, avg=10292.58, stdev=1100.27 clat percentiles (usec): | 1.00th=[ 7898], 5.00th=[ 8717], 10.00th=[ 9110], 20.00th=[ 9503], | 30.00th=[ 9765], 40.00th=[10028], 50.00th=[10290], 60.00th=[10421], | 70.00th=[10683], 80.00th=[11076], 90.00th=[11469], 95.00th=[11994], | 99.00th=[13173], 99.50th=[13829], 99.90th=[16057], 99.95th=[18220], | 99.99th=[38536] bw ( KiB/s): min=55680, max=68480, per=100.00%, avg=62153.14, stdev=187.66, samples=1190 iops : min= 870, max= 1070, avg=971.14, stdev= 2.93, samples=1190 lat (msec) : 4=0.01%, 10=39.02%, 20=60.96%, 50=0.03% cpu : usr=0.10%, sys=0.47%, ctx=58297, majf=0, minf=160 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=58239,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=60.7MiB/s (63.6MB/s), 60.7MiB/s-60.7MiB/s (63.6MB/s-63.6MB/s), io=3640MiB (3817MB), run=60008-60008msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file64kread_seq file64kread_seq: (g=0): rw=read, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [R(10)][90.0%][r=2123MiB/s][r=33.0k IOPS][eta 00m:01s] file64kread_seq: (groupid=0, jobs=10): err= 0: pid=2745510: Fri Sep 1 04:11:34 2023 read: IOPS=33.4k, BW=2087MiB/s (2189MB/s)(20.0GiB/9812msec) clat (usec): min=73, max=881, avg=298.74, stdev=74.16 lat (usec): min=73, max=882, avg=298.82, stdev=74.16 clat percentiles (usec): | 1.00th=[ 225], 5.00th=[ 241], 10.00th=[ 247], 20.00th=[ 253], | 30.00th=[ 262], 40.00th=[ 269], 50.00th=[ 273], 60.00th=[ 281], | 70.00th=[ 297], 80.00th=[ 322], 90.00th=[ 392], 95.00th=[ 457], | 99.00th=[ 611], 99.50th=[ 619], 99.90th=[ 660], 99.95th=[ 685], | 99.99th=[ 775] bw ( MiB/s): min= 1956, max= 2212, per=99.99%, avg=2087.01, stdev= 5.94, samples=190 iops : min=31300, max=35402, avg=33392.05, stdev=95.00, samples=190 lat (usec) : 100=0.01%, 250=14.41%, 500=81.87%, 750=3.71%, 1000=0.01% cpu : usr=0.55%, sys=3.44%, ctx=327760, majf=0, minf=161 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=327680,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=2087MiB/s (2189MB/s), 2087MiB/s-2087MiB/s (2189MB/s-2189MB/s), io=20.0GiB (21.5GB), run=9812-9812msec
64k Rand读测试
fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file64kread_rand
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file64kread_rand file64kread_rand: (g=0): rw=randread, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads file64kread_rand: Laying out IO file (1 file / 2048MiB) Jobs: 10 (f=10): [r(10)][95.0%][r=1108MiB/s][r=17.7k IOPS][eta 00m:01s] file64kread_rand: (groupid=0, jobs=10): err= 0: pid=51710: Thu Aug 31 03:35:44 2023 read: IOPS=17.4k, BW=1091MiB/s (1143MB/s)(20.0GiB/18780msec) clat (usec): min=153, max=2680, avg=566.33, stdev=99.22 lat (usec): min=153, max=2680, avg=566.91, stdev=99.20 clat percentiles (usec): | 1.00th=[ 351], 5.00th=[ 412], 10.00th=[ 445], 20.00th=[ 494], | 30.00th=[ 529], 40.00th=[ 562], 50.00th=[ 578], 60.00th=[ 594], | 70.00th=[ 603], 80.00th=[ 619], 90.00th=[ 652], 95.00th=[ 701], | 99.00th=[ 840], 99.50th=[ 922], 99.90th=[ 1221], 99.95th=[ 1713], | 99.99th=[ 2180] bw ( MiB/s): min= 1054, max= 1137, per=100.00%, avg=1093.54, stdev= 1.94, samples=370 iops : min=16870, max=18204, avg=17496.59, stdev=31.02, samples=370 lat (usec) : 250=0.22%, 500=21.83%, 750=75.44%, 1000=2.22% lat (msec) : 2=0.27%, 4=0.02% cpu : usr=0.30%, sys=2.84%, ctx=341493, majf=0, minf=40 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=327680,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=1091MiB/s (1143MB/s), 1091MiB/s-1091MiB/s (1143MB/s-1143MB/s), io=20.0GiB (21.5GB), run=18780-18780msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=60 -group_reporting -name=file64kread_rand file64kread_rand: (g=0): rw=randread, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=psync, iodepth=1 ... fio-3.33 Starting 10 threads Jobs: 10 (f=10): [r(10)][100.0%][r=58.7MiB/s][r=938 IOPS][eta 00m:00s] file64kread_rand: (groupid=0, jobs=10): err= 0: pid=20086: Thu Aug 31 15:35:06 2023 read: IOPS=961, BW=60.1MiB/s (63.0MB/s)(3606MiB/60006msec) clat (usec): min=5258, max=29652, avg=10386.14, stdev=1149.28 lat (usec): min=5259, max=29653, avg=10386.85, stdev=1149.28 clat percentiles (usec):大韩民国 | 1.00th=[ 7635], 5.00th=[ 8717], 10.00th=[ 9110], 20.00th=[ 9634], | 30.00th=[ 9896], 40.00th=[10159], 50.00th=[10290], 60.00th=[10552], | 70.00th=[10814], 80.00th=[11207], 90.00th=[11600], 95.00th=[12125], | 99.00th=[13435], 99.50th=[14222], 99.90th=[18482], 99.95th=[20579], | 99.99th=[27919] bw ( KiB/s): min=57600, max=71680, per=100.00%, avg=61581.98, stdev=227.81, samples=1190 iops : min= 900, max= 1120, avg=962.22, stdev= 3.56, samples=1190 lat (msec) : 10=35.13%, 20=64.80%, 50=0.06% cpu : usr=0.12%, sys=0.46%, ctx=57743, majf=0, minf=160 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=57695,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=60.1MiB/s (63.0MB/s), 60.1MiB/s-60.1MiB/s (63.0MB/s-63.0MB/s), io=3606MiB (3781MB), run=60006-60006msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=64k -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file64kread_rand file64kread_rand: (g=0): rw=randread, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [r(10)][100.0%][r=2040MiB/s][r=32.6k IOPS][eta 00m:00s] file64kread_rand: (groupid=0, jobs=10): err= 0: pid=2745589: Fri Sep 1 04:11:57 2023 read: IOPS=32.7k, BW=2045MiB/s (2144MB/s)(20.0GiB/10016msec) clat (usec): min=76, max=982, avg=304.76, stdev=83.29 lat (usec): min=76, max=982, avg=304.85, stdev=83.29 clat percentiles (usec): | 1.00th=[ 225], 5.00th=[ 235], 10.00th=[ 243], 20.00th=[ 253], | 30.00th=[ 262], 40.00th=[ 269], 50.00th=[ 277], 60.00th=[ 285], | 70.00th=[ 302], 80.00th=[ 338], 90.00th=[ 412], 95.00th=[ 502], | 99.00th=[ 611], 99.50th=[ 627], 99.90th=[ 685], 99.95th=[ 709], | 99.99th=[ 791] bw ( MiB/s): min= 1840, max= 2200, per=100.00%, avg=2047.46, stdev= 9.60, samples=199 iops : min=29452, max=35212, avg=32759.38, stdev=153.56, samples=199 lat (usec) : 100=0.01%, 250=16.85%, 500=78.05%, 750=5.08%, 1000=0.02% cpu : usr=0.54%, sys=3.45%, ctx=327716, majf=0, minf=161 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=327680,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=2045MiB/s (2144MB/s), 2045MiB/s-2045MiB/s (2144MB/s-2144MB/s), io=20.0GiB (21.5GB), run=10016-10016msec
1m
1m Seq写测试
fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file1mwrite_seq
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file1mwrite_seq file1mwrite_seq: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads file1mwrite_seq: Laying out IO file (1 file / 2048MiB) Jobs: 10 (f=10): [W(10)][100.0%][w=2332MiB/s][w=2332 IOPS][eta 00m:00s] file1mwrite_seq: (groupid=0, jobs=10): err= 0: pid=51759: Thu Aug 31 03:36:41 2023 write: IOPS=2314, BW=2315MiB/s (2427MB/s)(20.0GiB/8848msec); 0 zone resets clat (usec): min=1433, max=5813, avg=4298.85, stdev=222.98 lat (usec): min=1446, max=5820, avg=4311.51, stdev=222.90 clat percentiles (usec): | 1.00th=[ 3687], 5.00th=[ 3884], 10.00th=[ 4047], 20.00th=[ 4228], | 30.00th=[ 4228], 40.00th=[ 4293], 50.00th=[ 4293], 60.00th=[ 4293], | 70.00th=[ 4359], 80.00th=[ 4424], 90.00th=[ 4555], 95.00th=[ 4686], | 99.00th=[ 4883], 99.50th=[ 4948], 99.90th=[ 5211], 99.95th=[ 5342], | 99.99th=[ 5669] bw ( MiB/s): min= 2299, max= 2340, per=100.00%, avg=2317.88, stdev= 1.27, samples=170 iops : min= 2299, max= 2340, avg=2317.47, stdev= 1.28, samples=170 lat (msec) : 2=0.02%, 4=8.66%, 10=91.32% cpu : usr=0.56%, sys=1.17%, ctx=20536, majf=0, minf=0 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,20480,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=2315MiB/s (2427MB/s), 2315MiB/s-2315MiB/s (2427MB/s-2427MB/s), io=20.0GiB (21.5GB), run=8848-8848msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=60 -group_reporting -name=file1mwrite_seq file1mwrite_seq: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1 ... fio-3.33 Starting 10 threads file1mwrite_seq: Laying out IO file (1 file / 2048MiB) Jobs: 6 (f=6): [W(5),(1),W(1),(3)][100.0%][w=1045MiB/s][w=1045 IOPS][eta 00m:00s] file1mwrite_seq: (groupid=0, jobs=10): err= 0: pid=20199: Thu Aug 31 15:36:48 2023 write: IOPS=1209, BW=1210MiB/s (1269MB/s)(20.0GiB/16928msec); 0 zone resets clat (usec): min=2550, max=70080, avg=8131.78, stdev=2023.22 lat (usec): min=2627, max=70120, avg=8194.63, stdev=2028.35 clat percentiles (usec): | 1.00th=[ 4686], 5.00th=[ 5669], 10.00th=[ 6194], 20.00th=[ 6783], | 30.00th=[ 7242], 40.00th=[ 7635], 50.00th=[ 8029], 60.00th=[ 8455], | 70.00th=[ 8848], 80.00th=[ 9372], 90.00th=[10159], 95.00th=[10683], | 99.00th=[11994], 99.50th=[12649], 99.90th=[22414], 99.95th=[25560], | 99.99th=[68682] bw ( MiB/s): min= 1020, max= 1388, per=100.00%, avg=1218.18, stdev=10.14, samples=330 iops : min= 1020, max= 1388, avg=1218.18, stdev=10.14, samples=330 lat (msec) : 4=0.21%, 10=88.53%, 20=11.15%, 50=0.07%, 100=0.05% cpu : usr=0.95%, sys=2.15%, ctx=20577, majf=0, minf=0 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,20480,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=1210MiB/s (1269MB/s), 1210MiB/s-1210MiB/s (1269MB/s-1269MB/s), io=20.0GiB (21.5GB), run=16928-16928msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file1mwrite_seq file1mwrite_seq: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads file1mwrite_seq: Laying out IO file (1 file / 2048MiB) Jobs: 10 (f=10): [W(10)][100.0%][w=3934MiB/s][w=3933 IOPS][eta 00m:00s] file1mwrite_seq: (groupid=0, jobs=10): err= 0: pid=2745659: Fri Sep 1 04:12:17 2023 write: IOPS=3947, BW=3948MiB/s (4139MB/s)(20.0GiB/5188msec); 0 zone resets clat (usec): min=608, max=9803, avg=2490.31, stdev=596.21 lat (usec): min=634, max=9840, avg=2521.00, stdev=597.24 clat percentiles (usec): | 1.00th=[ 1385], 5.00th=[ 1696], 10.00th=[ 1844], 20.00th=[ 2024], | 30.00th=[ 2147], 40.00th=[ 2278], 50.00th=[ 2409], 60.00th=[ 2540], | 70.00th=[ 2704], 80.00th=[ 2933], 90.00th=[ 3228], 95.00th=[ 3523], | 99.00th=[ 4293], 99.50th=[ 4621], 99.90th=[ 5604], 99.95th=[ 6194], | 99.99th=[ 9634] bw ( MiB/s): min= 3842, max= 4100, per=100.00%, avg=3962.80, stdev= 8.03, samples=100 iops : min= 3842, max= 4100, avg=3962.80, stdev= 8.03, samples=100 lat (usec) : 750=0.14%, 1000=0.05% lat (msec) : 2=18.52%, 4=79.63%, 10=1.65% cpu : usr=1.29%, sys=3.62%, ctx=20510, majf=0, minf=2 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,20480,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=3948MiB/s (4139MB/s), 3948MiB/s-3948MiB/s (4139MB/s-4139MB/s), io=20.0GiB (21.5GB), run=5188-5188msec
1m Rand写测试
fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file1mwrite_rand
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file1mwrite_rand file1mwrite_rand: (g=0): rw=randwrite, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [w(10)][100.0%][w=2037MiB/s][w=2037 IOPS][eta 00m:00s] file1mwrite_rand: (groupid=0, jobs=10): err= 0: pid=51803: Thu Aug 31 03:37:50 2023 write: IOPS=2042, BW=2042MiB/s (2142MB/s)(20.0GiB/10027msec); 0 zone resets clat (usec): min=1511, max=6207, avg=4872.97, stdev=214.34 lat (usec): min=1524, max=6220, avg=4885.30, stdev=214.20 clat percentiles (usec): | 1.00th=[ 4293], 5.00th=[ 4490], 10.00th=[ 4686], 20.00th=[ 4752], | 30.00th=[ 4817], 40.00th=[ 4817], 50.00th=[ 4883], 60.00th=[ 4883], | 70.00th=[ 4948], 80.00th=[ 5014], 90.00th=[ 5080], 95.00th=[ 5211], | 99.00th=[ 5407], 99.50th=[ 5538], 99.90th=[ 5735], 99.95th=[ 5800], | 99.99th=[ 5997] bw ( MiB/s): min= 2021, max= 2060, per=100.00%, avg=2045.29, stdev= 1.13, samples=200 iops : min= 2021, max= 2060, avg=2044.40, stdev= 1.17, samples=200 lat (msec) : 2=0.03%, 4=0.19%, 10=99.79% cpu : usr=0.39%, sys=1.21%, ctx=20534, majf=0, minf=0 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,20480,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=2042MiB/s (2142MB/s), 2042MiB/s-2042MiB/s (2142MB/s-2142MB/s), io=20.0GiB (21.5GB), run=10027-10027msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=60 -group_reporting -name=file1mwrite_rand file1mwrite_rand: (g=0): rw=randwrite, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1 ... fio-3.33 Starting 10 threads Jobs: 10 (f=10): [w(10)][94.7%][w=1111MiB/s][w=1111 IOPS][eta 00m:01s] file1mwrite_rand: (groupid=0, jobs=10): err= 0: pid=20402: Thu Aug 31 15:37:51 2023 write: IOPS=1086, BW=1087MiB/s (1140MB/s)(20.0GiB/18843msec); 0 zone resets clat (usec): min=3102, max=16826, avg=9066.25, stdev=1533.30 lat (usec): min=3138, max=16851, avg=9147.58, stdev=1538.06 clat percentiles (usec): | 1.00th=[ 5407], 5.00th=[ 6587], 10.00th=[ 7111], 20.00th=[ 7767], | 30.00th=[ 8291], 40.00th=[ 8717], 50.00th=[ 9110], 60.00th=[ 9372], | 70.00th=[ 9896], 80.00th=[10290], 90.00th=[10945], 95.00th=[11600], | 99.00th=[12780], 99.50th=[13435], 99.90th=[14746], 99.95th=[15664], | 99.99th=[16188] bw ( MiB/s): min= 991, max= 1286, per=100.00%, avg=1088.32, stdev= 6.83, samples=370 iops : min= 991, max= 1286, avg=1088.30, stdev= 6.83, samples=370 lat (msec) : 4=0.05%, 10=73.41%, 20=26.54% cpu : usr=1.05%, sys=1.92%, ctx=20567, majf=0, minf=0 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,20480,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=1087MiB/s (1140MB/s), 1087MiB/s-1087MiB/s (1140MB/s-1140MB/s), io=20.0GiB (21.5GB), run=18843-18843msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file1mwrite_rand file1mwrite_rand: (g=0): rw=randwrite, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [w(10)][100.0%][w=3995MiB/s][w=3995 IOPS][eta 00m:00s] file1mwrite_rand: (groupid=0, jobs=10): err= 0: pid=2745732: Fri Sep 1 04:12:37 2023 write: IOPS=3980, BW=3981MiB/s (4174MB/s)(20.0GiB/5145msec); 0 zone resets clat (usec): min=626, max=7195, avg=2468.42, stdev=591.19 lat (usec): min=646, max=7227, avg=2498.69, stdev=592.28 clat percentiles (usec): | 1.00th=[ 1385], 5.00th=[ 1663], 10.00th=[ 1811], 20.00th=[ 1991], | 30.00th=[ 2147], 40.00th=[ 2245], 50.00th=[ 2376], 60.00th=[ 2540], | 70.00th=[ 2704], 80.00th=[ 2900], 90.00th=[ 3228], 95.00th=[ 3556], | 99.00th=[ 4228], 99.50th=[ 4490], 99.90th=[ 5342], 99.95th=[ 5735], | 99.99th=[ 6849] bw ( MiB/s): min= 3866, max= 4130, per=100.00%, avg=3990.92, stdev= 8.26, samples=100 iops : min= 3866, max= 4130, avg=3990.90, stdev= 8.26, samples=100 lat (usec) : 750=0.05%, 1000=0.06% lat (msec) : 2=20.56%, 4=77.53%, 10=1.79% cpu : usr=1.38%, sys=3.53%, ctx=20509, majf=0, minf=1 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=0,20480,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): WRITE: bw=3981MiB/s (4174MB/s), 3981MiB/s-3981MiB/s (4174MB/s-4174MB/s), io=20.0GiB (21.5GB), run=5145-5145msec
1m Seq读测试
fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file1mread_seq
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file1mread_seq file1mread_seq: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [R(10)][100.0%][r=2516MiB/s][r=2515 IOPS][eta 00m:00s] file1mread_seq: (groupid=0, jobs=10): err= 0: pid=51829: Thu Aug 31 03:38:18 2023 read: IOPS=2575, BW=2575MiB/s (2700MB/s)(20.0GiB/7953msec) clat (usec): min=736, max=8135, avg=3868.31, stdev=636.91 lat (usec): min=736, max=8136, avg=3868.96, stdev=636.89 clat percentiles (usec): | 1.00th=[ 2540], 5.00th=[ 3163], 10.00th=[ 3359], 20.00th=[ 3556], | 30.00th=[ 3621], 40.00th=[ 3687], 50.00th=[ 3752], 60.00th=[ 3818], | 70.00th=[ 3916], 80.00th=[ 4080], 90.00th=[ 4424], 95.00th=[ 5669], | 99.00th=[ 5932], 99.50th=[ 6063], 99.90th=[ 6980], 99.95th=[ 7177], | 99.99th=[ 7898] bw ( MiB/s): min= 2278, max= 2698, per=100.00%, avg=2579.02, stdev=12.74, samples=150 iops : min= 2278, max= 2698, avg=2578.40, stdev=12.69, samples=150 lat (usec) : 750=0.01%, 1000=0.03% lat (msec) : 2=0.24%, 4=74.79%, 10=24.93% cpu : usr=0.12%, sys=1.30%, ctx=20774, majf=0, minf=640 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=20480,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=2575MiB/s (2700MB/s), 2575MiB/s-2575MiB/s (2700MB/s-2700MB/s), io=20.0GiB (21.5GB), run=7953-7953msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=60 -group_reporting -name=file1mread_seq file1mread_seq: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1 ... fio-3.33 Starting 10 threads Jobs: 10 (f=10): [R(10)][100.0%][r=959MiB/s][r=959 IOPS][eta 00m:00s] file1mread_seq: (groupid=0, jobs=10): err= 0: pid=20483: Thu Aug 31 15:38:42 2023 read: IOPS=961, BW=962MiB/s (1008MB/s)(20.0GiB/21294msec) clat (usec): min=3009, max=58833, avg=10364.03, stdev=1447.52 lat (usec): min=3010, max=58834, avg=10364.79, stdev=1447.53 clat percentiles (usec): | 1.00th=[ 8717], 5.00th=[ 9110], 10.00th=[ 9372], 20.00th=[ 9634], | 30.00th=[ 9765], 40.00th=[ 9896], 50.00th=[10159], 60.00th=[10290], | 70.00th=[10552], 80.00th=[10945], 90.00th=[11600], 95.00th=[12387], | 99.00th=[13829], 99.50th=[14484], 99.90th=[16450], 99.95th=[17957], | 99.99th=[56886] bw ( KiB/s): min=860848, max=1028096, per=100.00%, avg=986380.48, stdev=3305.89, samples=420 iops : min= 840, max= 1004, avg=963.24, stdev= 3.24, samples=420 lat (msec) : 4=0.01%, 10=43.72%, 20=56.22%, 100=0.05% cpu : usr=0.11%, sys=1.64%, ctx=20533, majf=0, minf=1042 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=20480,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=962MiB/s (1008MB/s), 962MiB/s-962MiB/s (1008MB/s-1008MB/s), io=20.0GiB (21.5GB), run=21294-21294msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file1mread_seq file1mread_seq: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [R(10)][100.0%][r=3826MiB/s][r=3825 IOPS][eta 00m:00s] file1mread_seq: (groupid=0, jobs=10): err= 0: pid=2745810: Fri Sep 1 04:12:55 2023 read: IOPS=3872, BW=3872MiB/s (4060MB/s)(20.0GiB/5289msec) clat (usec): min=446, max=7990, avg=2577.26, stdev=253.44 lat (usec): min=446, max=7991, avg=2577.50, stdev=253.45 clat percentiles (usec): | 1.00th=[ 2040], 5.00th=[ 2245], 10.00th=[ 2376], 20.00th=[ 2474], | 30.00th=[ 2507], 40.00th=[ 2540], 50.00th=[ 2573], 60.00th=[ 2606], | 70.00th=[ 2638], 80.00th=[ 2671], 90.00th=[ 2769], 95.00th=[ 2868], | 99.00th=[ 3458], 99.50th=[ 3851], 99.90th=[ 5276], 99.95th=[ 5800], | 99.99th=[ 6849] bw ( MiB/s): min= 3668, max= 4018, per=100.00%, avg=3877.05, stdev=10.08, samples=100 iops : min= 3668, max= 4018, avg=3877.00, stdev=10.09, samples=100 lat (usec) : 500=0.02%, 750=0.01% lat (msec) : 2=0.66%, 4=98.92%, 10=0.39% cpu : usr=0.17%, sys=4.50%, ctx=20538, majf=0, minf=2055 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=20480,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=3872MiB/s (4060MB/s), 3872MiB/s-3872MiB/s (4060MB/s-4060MB/s), io=20.0GiB (21.5GB), run=5289-5289msec
1m Rand读测试
fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file1mread_rand
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file1mread_rand file1mread_rand: (g=0): rw=randread, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [r(10)][100.0%][r=2416MiB/s][r=2416 IOPS][eta 00m:00s] file1mread_rand: (groupid=0, jobs=10): err= 0: pid=51846: Thu Aug 31 03:39:05 2023 read: IOPS=2465, BW=2465MiB/s (2585MB/s)(20.0GiB/8308msec) clat (usec): min=800, max=8163, avg=4041.99, stdev=766.98 lat (usec): min=801, max=8164, avg=4042.67, stdev=766.96 clat percentiles (usec): | 1.00th=[ 2573], 5.00th=[ 3195], 10.00th=[ 3359], 20.00th=[ 3589], | 30.00th=[ 3687], 40.00th=[ 3752], 50.00th=[ 3884], 60.00th=[ 4015], | 70.00th=[ 4178], 80.00th=[ 4359], 90.00th=[ 4817], 95.00th=[ 5932], | 99.00th=[ 6652], 99.50th=[ 6718], 99.90th=[ 7046], 99.95th=[ 7242], | 99.99th=[ 7898] bw ( MiB/s): min= 2141, max= 2625, per=100.00%, avg=2465.18, stdev=14.19, samples=160 iops : min= 2136, max= 2622, avg=2463.25, stdev=14.26, samples=160 lat (usec) : 1000=0.03% lat (msec) : 2=0.22%, 4=58.43%, 10=41.31% cpu : usr=0.19%, sys=1.27%, ctx=20599, majf=0, minf=640 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=20480,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=2465MiB/s (2585MB/s), 2465MiB/s-2465MiB/s (2585MB/s-2585MB/s), io=20.0GiB (21.5GB), run=8308-8308msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=60 -group_reporting -name=file1mread_rand file1mread_rand: (g=0): rw=randread, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1 ... fio-3.33 Starting 10 threads Jobs: 10 (f=10): [r(10)][100.0%][r=938MiB/s][r=937 IOPS][eta 00m:00s] file1mread_rand: (groupid=0, jobs=10): err= 0: pid=20561: Thu Aug 31 15:39:23 2023 read: IOPS=965, BW=966MiB/s (1012MB/s)(20.0GiB/21210msec) clat (usec): min=2080, max=25804, avg=10312.17, stdev=1421.04 lat (usec): min=2080, max=25805, avg=10312.86, stdev=1421.05 clat percentiles (usec): | 1.00th=[ 7242], 5.00th=[ 8029], 10.00th=[ 8586], 20.00th=[ 9241], | 30.00th=[ 9634], 40.00th=[10028], 50.00th=[10290], 60.00th=[10552], | 70.00th=[10945], 80.00th=[11338], 90.00th=[11994], 95.00th=[12649], | 99.00th=[13960], 99.50th=[14484], 99.90th=[16188], 99.95th=[18744], | 99.99th=[25560] bw ( KiB/s): min=919552, max=1132544, per=100.00%, avg=989418.19, stdev=5190.91, samples=420 iops : min= 898, max= 1106, avg=966.19, stdev= 5.07, samples=420 lat (msec) : 4=0.06%, 10=39.97%, 20=59.92%, 50=0.05% cpu : usr=0.13%, sys=1.80%, ctx=20534, majf=0, minf=2054 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=20480,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=966MiB/s (1012MB/s), 966MiB/s-966MiB/s (1012MB/s-1012MB/s), io=20.0GiB (21.5GB), run=21210-21210msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/1m -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=1m -size=2G -numjobs=10 -runtime=600 -group_reporting -name=file1mread_rand file1mread_rand: (g=0): rw=randread, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=psync, iodepth=1 ... fio-3.22 Starting 10 threads Jobs: 10 (f=10): [r(10)][100.0%][r=3657MiB/s][r=3656 IOPS][eta 00m:00s] file1mread_rand: (groupid=0, jobs=10): err= 0: pid=2745878: Fri Sep 1 04:13:13 2023 read: IOPS=3772, BW=3772MiB/s (3956MB/s)(20.0GiB/5429msec) clat (usec): min=542, max=6264, avg=2645.44, stdev=232.60 lat (usec): min=542, max=6264, avg=2645.64, stdev=232.59 clat percentiles (usec): | 1.00th=[ 2089], 5.00th=[ 2311], 10.00th=[ 2442], 20.00th=[ 2507], | 30.00th=[ 2573], 40.00th=[ 2606], 50.00th=[ 2638], 60.00th=[ 2671], | 70.00th=[ 2704], 80.00th=[ 2769], 90.00th=[ 2835], 95.00th=[ 2900], | 99.00th=[ 3261], 99.50th=[ 3523], 99.90th=[ 5407], 99.95th=[ 5932], | 99.99th=[ 6259] bw ( MiB/s): min= 3610, max= 3892, per=100.00%, avg=3774.80, stdev= 8.40, samples=100 iops : min= 3610, max= 3892, avg=3774.80, stdev= 8.40, samples=100 lat (usec) : 750=0.01%, 1000=0.02% lat (msec) : 2=0.43%, 4=99.27%, 10=0.27% cpu : usr=0.13%, sys=3.71%, ctx=20521, majf=0, minf=1043 IO depths : 1=100.0%, 2=0.0%, 4=0.0%, 8=0.0%, 16=0.0%, 32=0.0%, >=64=0.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% issued rwts: total=20480,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=1
Run status group 0 (all jobs): READ: bw=3772MiB/s (3956MB/s), 3772MiB/s-3772MiB/s (3956MB/s-3956MB/s), io=20.0GiB (21.5GB), run=5429-5429msec
Anyway
16k write libaio No_rand iodepth_128 numjobs_1
fio -filename=/mnt/mem1/16k -direct=1 -iodepth 128 -thread -rw=write -ioengine=libaio -bs=16k -size=2G -numjobs=1 -runtime=600 -group_reporting -name=file16kwrite_seq
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/16k -direct=1 -iodepth 128 -thread -rw=write -ioengine=libaio -bs=16k -size=2G -numjobs=1 -runtime=600 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=write, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=libaio, iodepth=128 fio-3.22 Starting 1 thread file16kwrite_seq: Laying out IO file (1 file / 2048MiB) Jobs: 1 (f=1): [W(1)][100.0%][w=436MiB/s][w=27.9k IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=51900: Thu Aug 31 03:40:33 2023 write: IOPS=27.9k, BW=436MiB/s (458MB/s)(2048MiB/4693msec); 0 zone resets slat (nsec): min=3070, max=42160, avg=5104.98, stdev=743.49 clat (usec): min=795, max=8566, avg=4574.56, stdev=349.47 lat (usec): min=802, max=8572, avg=4580.11, stdev=349.54 clat percentiles (usec): | 1.00th=[ 3359], 5.00th=[ 4178], 10.00th=[ 4293], 20.00th=[ 4424], | 30.00th=[ 4490], 40.00th=[ 4555], 50.00th=[ 4555], 60.00th=[ 4621], | 70.00th=[ 4686], 80.00th=[ 4752], 90.00th=[ 4817], 95.00th=[ 4948], | 99.00th=[ 5735], 99.50th=[ 6194], 99.90th=[ 6915], 99.95th=[ 7046], | 99.99th=[ 8094] bw ( KiB/s): min=444128, max=459712, per=100.00%, avg=447505.78, stdev=4906.74, samples=9 iops : min=27758, max=28732, avg=27969.11, stdev=306.67, samples=9 lat (usec) : 1000=0.01% lat (msec) : 2=0.02%, 4=3.40%, 10=96.58% cpu : usr=2.45%, sys=26.60%, ctx=102406, majf=0, minf=0 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=0,131072,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): WRITE: bw=436MiB/s (458MB/s), 436MiB/s-436MiB/s (458MB/s-458MB/s), io=2048MiB (2147MB), run=4693-4693msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/16k -direct=1 -iodepth 128 -thread -rw=write -ioengine=libaio -bs=16k -size=2G -numjobs=1 -runtime=60 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=write, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=libaio, iodepth=128 fio-3.33 Starting 1 thread Jobs: 1 (f=1): [W(1)][100.0%][w=16.4MiB/s][w=1051 IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=20772: Thu Aug 31 15:43:08 2023 write: IOPS=1052, BW=16.5MiB/s (17.3MB/s)(988MiB/60075msec); 0 zone resets slat (usec): min=3, max=323, avg=23.73, stdev= 8.95 clat (msec): min=7, max=194, avg=121.51, stdev= 6.02 lat (msec): min=7, max=194, avg=121.54, stdev= 6.02 clat percentiles (msec): | 1.00th=[ 109], 5.00th=[ 114], 10.00th=[ 116], 20.00th=[ 118], | 30.00th=[ 120], 40.00th=[ 121], 50.00th=[ 122], 60.00th=[ 123], | 70.00th=[ 124], 80.00th=[ 125], 90.00th=[ 127], 95.00th=[ 129], | 99.00th=[ 140], 99.50th=[ 144], 99.90th=[ 180], 99.95th=[ 182], | 99.99th=[ 188] bw ( KiB/s): min=14304, max=18304, per=99.92%, avg=16834.93, stdev=484.40, samples=120 iops : min= 894, max= 1144, avg=1052.18, stdev=30.27, samples=120 lat (msec) : 10=0.01%, 20=0.01%, 50=0.02%, 100=0.12%, 250=99.85% cpu : usr=1.12%, sys=4.00%, ctx=63239, majf=0, minf=63 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=99.9% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=0,63258,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): WRITE: bw=16.5MiB/s (17.3MB/s), 16.5MiB/s-16.5MiB/s (17.3MB/s-17.3MB/s), io=988MiB (1036MB), run=60075-60075msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/16k -direct=1 -iodepth 128 -thread -rw=write -ioengine=libaio -bs=16k -size=2G -numjobs=1 -runtime=600 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=write, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=libaio, iodepth=128 fio-3.22 Starting 1 thread Jobs: 1 (f=1) file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=2745950: Fri Sep 1 04:13:28 2023 write: IOPS=54.8k, BW=856MiB/s (897MB/s)(2048MiB/2393msec); 0 zone resets slat (nsec): min=2190, max=76940, avg=4543.53, stdev=1154.25 clat (usec): min=635, max=5527, avg=2330.78, stdev=250.71 lat (usec): min=640, max=5532, avg=2335.36, stdev=250.81 clat percentiles (usec): | 1.00th=[ 2040], 5.00th=[ 2089], 10.00th=[ 2114], 20.00th=[ 2147], | 30.00th=[ 2180], 40.00th=[ 2245], 50.00th=[ 2278], 60.00th=[ 2311], | 70.00th=[ 2376], 80.00th=[ 2442], 90.00th=[ 2606], 95.00th=[ 2769], | 99.00th=[ 3294], 99.50th=[ 3621], 99.90th=[ 4424], 99.95th=[ 5014], | 99.99th=[ 5473] bw ( KiB/s): min=862976, max=895872, per=100.00%, avg=880456.00, stdev=14473.96, samples=4 iops : min=53936, max=55992, avg=55028.50, stdev=904.62, samples=4 lat (usec) : 750=0.01%, 1000=0.01% lat (msec) : 2=0.53%, 4=99.32%, 10=0.14% cpu : usr=9.28%, sys=30.43%, ctx=99717, majf=0, minf=2 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=0,131072,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): WRITE: bw=856MiB/s (897MB/s), 856MiB/s-856MiB/s (897MB/s-897MB/s), io=2048MiB (2147MB), run=2393-2393msec
16k read libaio No_rand iodepth_128 numjobs_1
fio -filename=/mnt/mem1/16k -direct=1 -iodepth 128 -thread -rw=read -ioengine=libaio -bs=16k -size=2G -numjobs=1 -runtime=600 -group_reporting -name=file16kwrite_seq
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/16k -direct=1 -iodepth 128 -thread -rw=read -ioengine=libaio -bs=16k -size=2G -numjobs=1 -runtime=600 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=read, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=libaio, iodepth=128 fio-3.22 Starting 1 thread Jobs: 1 (f=1): [R(1)][100.0%][r=484MiB/s][r=30.0k IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=51946: Thu Aug 31 03:43:41 2023 read: IOPS=30.8k, BW=481MiB/s (504MB/s)(2048MiB/4260msec) slat (nsec): min=2580, max=49830, avg=4812.34, stdev=1096.46 clat (usec): min=1053, max=9127, avg=4150.72, stdev=474.74 lat (usec): min=1061, max=9133, avg=4155.98, stdev=474.78 clat percentiles (usec): | 1.00th=[ 2868], 5.00th=[ 3490], 10.00th=[ 3654], 20.00th=[ 3818], | 30.00th=[ 3916], 40.00th=[ 4015], 50.00th=[ 4113], 60.00th=[ 4228], | 70.00th=[ 4359], 80.00th=[ 4490], 90.00th=[ 4686], 95.00th=[ 4883], | 99.00th=[ 5538], 99.50th=[ 5800], 99.90th=[ 6259], 99.95th=[ 6587], | 99.99th=[ 8717] bw ( KiB/s): min=470944, max=518912, per=100.00%, avg=494028.00, stdev=18219.10, samples=8 iops : min=29434, max=32432, avg=30876.75, stdev=1138.69, samples=8 lat (msec) : 2=0.03%, 4=38.31%, 10=61.66% cpu : usr=3.87%, sys=25.80%, ctx=81782, majf=0, minf=128 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=131072,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): READ: bw=481MiB/s (504MB/s), 481MiB/s-481MiB/s (504MB/s-504MB/s), io=2048MiB (2147MB), run=4260-4260msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/16k -direct=1 -iodepth 128 -thread -rw=read -ioengine=libaio -bs=16k -size=2G -numjobs=1 -runtime=60 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=read, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=libaio, iodepth=128 fio-3.33 Starting 1 thread Jobs: 1 (f=1): [R(1)][100.0%][r=15.1MiB/s][r=966 IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=20855: Thu Aug 31 15:44:45 2023 read: IOPS=959, BW=15.0MiB/s (15.7MB/s)(901MiB/60078msec) slat (usec): min=4, max=531, avg=23.89, stdev= 7.57 clat (msec): min=8, max=211, avg=133.31, stdev= 7.16 lat (msec): min=8, max=211, avg=133.34, stdev= 7.16 clat percentiles (msec): | 1.00th=[ 115], 5.00th=[ 124], 10.00th=[ 127], 20.00th=[ 131], | 30.00th=[ 132], 40.00th=[ 134], 50.00th=[ 134], 60.00th=[ 136], | 70.00th=[ 136], 80.00th=[ 138], 90.00th=[ 138], 95.00th=[ 140], | 99.00th=[ 150], 99.50th=[ 171], 99.90th=[ 207], 99.95th=[ 209], | 99.99th=[ 211] bw ( KiB/s): min=13920, max=17280, per=99.91%, avg=15342.67, stdev=500.46, samples=120 iops : min= 870, max= 1080, avg=958.92, stdev=31.28, samples=120 lat (msec) : 10=0.01%, 20=0.01%, 50=0.02%, 100=0.12%, 250=99.85% cpu : usr=0.98%, sys=3.90%, ctx=57678, majf=0, minf=571 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=99.9% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=57662,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): READ: bw=15.0MiB/s (15.7MB/s), 15.0MiB/s-15.0MiB/s (15.7MB/s-15.7MB/s), io=901MiB (945MB), run=60078-60078msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/16k -direct=1 -iodepth 128 -thread -rw=read -ioengine=libaio -bs=16k -size=2G -numjobs=1 -runtime=600 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=read, bs=(R) 16.0KiB-16.0KiB, (W) 16.0KiB-16.0KiB, (T) 16.0KiB-16.0KiB, ioengine=libaio, iodepth=128 fio-3.22 Starting 1 thread Jobs: 1 (f=1) file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=2746024: Fri Sep 1 04:13:55 2023 read: IOPS=55.6k, BW=869MiB/s (911MB/s)(2048MiB/2356msec) slat (nsec): min=1749, max=39694, avg=3998.16, stdev=1184.86 clat (usec): min=1461, max=4455, avg=2294.29, stdev=338.58 lat (usec): min=1465, max=4460, avg=2298.32, stdev=338.61 clat percentiles (usec): | 1.00th=[ 1795], 5.00th=[ 1975], 10.00th=[ 2008], 20.00th=[ 2057], | 30.00th=[ 2114], 40.00th=[ 2147], 50.00th=[ 2212], 60.00th=[ 2278], | 70.00th=[ 2343], 80.00th=[ 2474], 90.00th=[ 2737], 95.00th=[ 3064], | 99.00th=[ 3556], 99.50th=[ 3654], 99.90th=[ 4113], 99.95th=[ 4228], | 99.99th=[ 4359] bw ( KiB/s): min=866491, max=909504, per=99.48%, avg=885534.75, stdev=22194.85, samples=4 iops : min=54155, max=56844, avg=55345.75, stdev=1387.38, samples=4 lat (msec) : 2=7.75%, 4=92.11%, 10=0.15% cpu : usr=7.60%, sys=30.83%, ctx=108990, majf=0, minf=514 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=131072,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): READ: bw=869MiB/s (911MB/s), 869MiB/s-869MiB/s (911MB/s-911MB/s), io=2048MiB (2147MB), run=2356-2356msec
64k write libaio No_rand iodepth_128 numjobs_1
fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=write -ioengine=libaio -bs=64k -size=4G -numjobs=1 -runtime=600 -group_reporting -name=file16kwrite_seq
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=write -ioengine=libaio -bs=64k -size=4G -numjobs=1 -runtime=600 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=write, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=libaio, iodepth=128 fio-3.22 Starting 1 thread file16kwrite_seq: Laying out IO file (1 file / 4096MiB) Jobs: 1 (f=1): [W(1)][100.0%][w=1104MiB/s][w=17.7k IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=51993: Thu Aug 31 03:45:21 2023 write: IOPS=17.9k, BW=1118MiB/s (1172MB/s)(4096MiB/3664msec); 0 zone resets slat (nsec): min=4620, max=53160, avg=7778.05, stdev=1146.85 clat (usec): min=1073, max=13136, avg=7143.14, stdev=466.51 lat (usec): min=1080, max=13143, avg=7151.38, stdev=466.52 clat percentiles (usec): | 1.00th=[ 5800], 5.00th=[ 6521], 10.00th=[ 6783], 20.00th=[ 6915], | 30.00th=[ 7046], 40.00th=[ 7111], 50.00th=[ 7177], 60.00th=[ 7242], | 70.00th=[ 7308], 80.00th=[ 7373], 90.00th=[ 7439], 95.00th=[ 7635], | 99.00th=[ 8848], 99.50th=[ 9241], 99.90th=[10159], 99.95th=[11207], | 99.99th=[12780] bw ( MiB/s): min= 1098, max= 1143, per=100.00%, avg=1119.59, stdev=17.62, samples=7 iops : min=17580, max=18300, avg=17913.43, stdev=281.91, samples=7 lat (msec) : 2=0.02%, 4=0.12%, 10=99.74%, 20=0.12% cpu : usr=6.47%, sys=17.85%, ctx=55880, majf=0, minf=0 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=99.9% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=0,65536,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): WRITE: bw=1118MiB/s (1172MB/s), 1118MiB/s-1118MiB/s (1172MB/s-1172MB/s), io=4096MiB (4295MB), run=3664-3664msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=write -ioengine=libaio -bs=64k -size=4G -numjobs=1 -runtime=60 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=write, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=libaio, iodepth=128 fio-3.33 Starting 1 thread file16kwrite_seq: Laying out IO file (1 file / 4096MiB) Jobs: 1 (f=1): [W(1)][100.0%][w=65.4MiB/s][w=1046 IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=20955: Thu Aug 31 15:46:24 2023 write: IOPS=1088, BW=68.0MiB/s (71.3MB/s)(4085MiB/60075msec); 0 zone resets slat (usec): min=5, max=533, avg=32.33, stdev= 9.84 clat (msec): min=2, max=197, avg=117.58, stdev=16.71 lat (msec): min=2, max=197, avg=117.61, stdev=16.71 clat percentiles (msec): | 1.00th=[ 55], 5.00th=[ 70], 10.00th=[ 99], 20.00th=[ 120], | 30.00th=[ 121], 40.00th=[ 122], 50.00th=[ 123], 60.00th=[ 124], | 70.00th=[ 125], 80.00th=[ 126], 90.00th=[ 128], 95.00th=[ 129], | 99.00th=[ 136], 99.50th=[ 142], 99.90th=[ 161], 99.95th=[ 165], | 99.99th=[ 190] bw ( KiB/s): min=61819, max=139776, per=99.96%, avg=69613.56, stdev=11807.92, samples=120 iops : min= 965, max= 2184, avg=1087.69, stdev=184.51, samples=120 lat (msec) : 4=0.01%, 10=0.01%, 20=0.02%, 50=0.26%, 100=9.96% lat (msec) : 250=89.75% cpu : usr=1.63%, sys=4.50%, ctx=65349, majf=0, minf=113 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=99.9% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=0,65367,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): WRITE: bw=68.0MiB/s (71.3MB/s), 68.0MiB/s-68.0MiB/s (71.3MB/s-71.3MB/s), io=4085MiB (4284MB), run=60075-60075msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=write -ioengine=libaio -bs=64k -size=4G -numjobs=1 -runtime=600 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=write, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=libaio, iodepth=128 fio-3.22 Starting 1 thread file16kwrite_seq: Laying out IO file (1 file / 4096MiB) Jobs: 1 (f=1) file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=2746084: Fri Sep 1 04:14:13 2023 write: IOPS=37.1k, BW=2319MiB/s (2432MB/s)(4096MiB/1766msec); 0 zone resets slat (nsec): min=3811, max=67897, avg=8061.79, stdev=2885.44 clat (usec): min=1301, max=6983, avg=3436.88, stdev=607.29 lat (usec): min=1316, max=6999, avg=3444.99, stdev=607.34 clat percentiles (usec): | 1.00th=[ 2474], 5.00th=[ 2737], 10.00th=[ 2835], 20.00th=[ 2966], | 30.00th=[ 3064], 40.00th=[ 3163], 50.00th=[ 3294], 60.00th=[ 3425], | 70.00th=[ 3589], 80.00th=[ 3851], 90.00th=[ 4293], 95.00th=[ 4621], | 99.00th=[ 5407], 99.50th=[ 5735], 99.90th=[ 6521], 99.95th=[ 6652], | 99.99th=[ 6915] bw ( MiB/s): min= 2305, max= 2336, per=99.87%, avg=2316.33, stdev=17.26, samples=3 iops : min=36892, max=37380, avg=37061.33, stdev=276.15, samples=3 lat (msec) : 2=0.06%, 4=83.81%, 10=16.13% cpu : usr=9.97%, sys=28.50%, ctx=36311, majf=0, minf=2 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=99.9% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=0,65536,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): WRITE: bw=2319MiB/s (2432MB/s), 2319MiB/s-2319MiB/s (2432MB/s-2432MB/s), io=4096MiB (4295MB), run=1766-1766msec
64k read libaio No_rand iodepth_128 numjobs_1
fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=read -ioengine=libaio -bs=64k -size=2G -numjobs=1 -group_reporting -name=file16kwrite_seq
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=read -ioengine=libaio -bs=64k -size=10G -numjobs=1 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=read, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=libaio, iodepth=128 fio-3.22 Starting 1 thread file16kwrite_seq: Laying out IO file (1 file / 10240MiB) Jobs: 1 (f=1): [R(1)][100.0%][r=1122MiB/s][r=17.0k IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=52041: Thu Aug 31 03:47:30 2023 read: IOPS=18.1k, BW=1133MiB/s (1188MB/s)(10.0GiB/9037msec) slat (usec): min=3, max=466, avg= 8.08, stdev= 9.10 clat (usec): min=1891, max=12842, avg=6925.51, stdev=595.04 lat (usec): min=1924, max=12850, avg=6934.20, stdev=594.30 clat percentiles (usec): | 1.00th=[ 5145], 5.00th=[ 6194], 10.00th=[ 6390], 20.00th=[ 6521], | 30.00th=[ 6652], 40.00th=[ 6783], 50.00th=[ 6915], 60.00th=[ 7046], | 70.00th=[ 7242], 80.00th=[ 7308], 90.00th=[ 7504], 95.00th=[ 7701], | 99.00th=[ 8717], 99.50th=[ 9372], 99.90th=[10421], 99.95th=[10945], | 99.99th=[11994] bw ( MiB/s): min= 766, max= 1195, per=100.00%, avg=1134.56, stdev=96.75, samples=18 iops : min=12267, max=19120, avg=18152.89, stdev=1548.08, samples=18 lat (msec) : 2=0.01%, 4=0.19%, 10=99.63%, 20=0.18% cpu : usr=4.69%, sys=20.00%, ctx=150099, majf=0, minf=512 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=100.0% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=163840,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): READ: bw=1133MiB/s (1188MB/s), 1133MiB/s-1133MiB/s (1188MB/s-1188MB/s), io=10.0GiB (10.7GB), run=9037-9037msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=read -ioengine=libaio -bs=64k -size=2G -numjobs=1 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=read, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=libaio, iodepth=128 fio-3.33 Starting 1 thread Jobs: 1 (f=0): [f(1)][100.0%][r=60.2MiB/s][r=962 IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=21166: Thu Aug 31 15:48:23 2023 read: IOPS=997, BW=62.4MiB/s (65.4MB/s)(2048MiB/32838msec) slat (usec): min=6, max=2764, avg=30.73, stdev=24.70 clat (msec): min=7, max=216, avg=128.19, stdev= 8.17 lat (msec): min=7, max=216, avg=128.22, stdev= 8.17 clat percentiles (msec): | 1.00th=[ 110], 5.00th=[ 117], 10.00th=[ 121], 20.00th=[ 124], | 30.00th=[ 126], 40.00th=[ 128], 50.00th=[ 130], 60.00th=[ 131], | 70.00th=[ 132], 80.00th=[ 133], 90.00th=[ 136], 95.00th=[ 136], | 99.00th=[ 140], 99.50th=[ 178], 99.90th=[ 188], 99.95th=[ 201], | 99.99th=[ 213] bw ( KiB/s): min=53888, max=72576, per=99.96%, avg=63840.49, stdev=2838.64, samples=65 iops : min= 842, max= 1134, avg=997.51, stdev=44.35, samples=65 lat (msec) : 10=0.01%, 20=0.02%, 50=0.05%, 100=0.12%, 250=99.80% cpu : usr=1.03%, sys=4.80%, ctx=32772, majf=0, minf=547 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=99.8% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=32768,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): READ: bw=62.4MiB/s (65.4MB/s), 62.4MiB/s-62.4MiB/s (65.4MB/s-65.4MB/s), io=2048MiB (2147MB), run=32838-32838msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=read -ioengine=libaio -bs=64k -size=2G -numjobs=1 -group_reporting -name=file16kwrite_seq file16kwrite_seq: (g=0): rw=read, bs=(R) 64.0KiB-64.0KiB, (W) 64.0KiB-64.0KiB, (T) 64.0KiB-64.0KiB, ioengine=libaio, iodepth=128 fio-3.22 Starting 1 thread Jobs: 1 (f=1) file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=2746151: Fri Sep 1 04:14:31 2023 read: IOPS=31.0k, BW=1939MiB/s (2034MB/s)(2048MiB/1056msec) slat (usec): min=2, max=323, avg= 6.46, stdev= 4.03 clat (usec): min=2118, max=9392, avg=4106.42, stdev=967.53 lat (usec): min=2137, max=9398, avg=4112.92, stdev=967.36 clat percentiles (usec): | 1.00th=[ 2933], 5.00th=[ 3294], 10.00th=[ 3326], 20.00th=[ 3425], | 30.00th=[ 3490], 40.00th=[ 3556], 50.00th=[ 3687], 60.00th=[ 3851], | 70.00th=[ 4293], 80.00th=[ 4817], 90.00th=[ 5604], 95.00th=[ 6194], | 99.00th=[ 7177], 99.50th=[ 7439], 99.90th=[ 8225], 99.95th=[ 8848], | 99.99th=[ 9241] bw ( MiB/s): min= 1918, max= 1984, per=100.00%, avg=1951.56, stdev=46.40, samples=2 iops : min=30700, max=31750, avg=31225.00, stdev=742.46, samples=2 lat (msec) : 4=64.21%, 10=35.79% cpu : usr=4.55%, sys=25.59%, ctx=30651, majf=0, minf=517 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.1%, 32=0.1%, >=64=99.8% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=32768,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): READ: bw=1939MiB/s (2034MB/s), 1939MiB/s-1939MiB/s (2034MB/s-2034MB/s), io=2048MiB (2147MB), run=1056-1056msec
1m write libaio No_rand iodepth_128 numjobs_1
fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=write -ioengine=libaio -bs=1m -size=10G -numjobs=1 -group_reporting -name=file16kwrite_seq -runtime 600
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=write -ioengine=libaio -bs=1m -size=10G -numjobs=1 -group_reporting -name=file16kwrite_seq -runtime 600 file16kwrite_seq: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=libaio, iodepth=128 fio-3.22 Starting 1 thread Jobs: 1 (f=1): [W(1)][100.0%][w=2054MiB/s][w=2054 IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=52245: Thu Aug 31 03:57:16 2023 write: IOPS=2059, BW=2060MiB/s (2160MB/s)(10.0GiB/4972msec); 0 zone resets slat (usec): min=31, max=189, avg=54.00, stdev=10.09 clat (msec): min=13, max=119, avg=61.98, stdev= 5.21 lat (msec): min=13, max=119, avg=62.04, stdev= 5.21 clat percentiles (msec): | 1.00th=[ 47], 5.00th=[ 62], 10.00th=[ 62], 20.00th=[ 62], | 30.00th=[ 62], 40.00th=[ 62], 50.00th=[ 62], 60.00th=[ 63], | 70.00th=[ 63], 80.00th=[ 63], 90.00th=[ 64], 95.00th=[ 65], | 99.00th=[ 69], 99.50th=[ 94], 99.90th=[ 114], 99.95th=[ 117], | 99.99th=[ 120] bw ( MiB/s): min= 1998, max= 2092, per=100.00%, avg=2062.44, stdev=29.32, samples=9 iops : min= 1998, max= 2092, avg=2062.44, stdev=29.32, samples=9 lat (msec) : 20=0.35%, 50=0.71%, 100=98.54%, 250=0.39% cpu : usr=5.45%, sys=8.69%, ctx=10130, majf=0, minf=0 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.2%, 32=0.3%, >=64=99.4% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=0,10240,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): WRITE: bw=2060MiB/s (2160MB/s), 2060MiB/s-2060MiB/s (2160MB/s-2160MB/s), io=10.0GiB (10.7GB), run=4972-4972msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=write -ioengine=libaio -bs=1m -size=10G -numjobs=1 -group_reporting -name=file16kwrite_seq -runtime 60 file16kwrite_seq: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=libaio, iodepth=128 fio-3.33 Starting 1 thread Jobs: 1 (f=1): [W(1)][100.0%][w=1035MiB/s][w=1035 IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=21981: Thu Aug 31 15:57:36 2023 write: IOPS=1019, BW=1020MiB/s (1069MB/s)(10.0GiB/10040msec); 0 zone resets slat (usec): min=85, max=3240, avg=229.29, stdev=63.46 clat (msec): min=19, max=208, avg=125.06, stdev=12.88 lat (msec): min=19, max=208, avg=125.29, stdev=12.88 clat percentiles (msec): | 1.00th=[ 91], 5.00th=[ 114], 10.00th=[ 117], 20.00th=[ 121], | 30.00th=[ 122], 40.00th=[ 124], 50.00th=[ 125], 60.00th=[ 127], | 70.00th=[ 128], 80.00th=[ 131], 90.00th=[ 136], 95.00th=[ 140], | 99.00th=[ 180], 99.50th=[ 188], 99.90th=[ 203], 99.95th=[ 207], | 99.99th=[ 209] bw ( KiB/s): min=866304, max=1107968, per=99.15%, avg=1035571.20, stdev=53472.54, samples=20 iops : min= 846, max= 1082, avg=1011.30, stdev=52.22, samples=20 lat (msec) : 20=0.04%, 50=0.40%, 100=0.81%, 250=98.75% cpu : usr=12.83%, sys=12.45%, ctx=8264, majf=0, minf=93 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.2%, 32=0.3%, >=64=99.4% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=0,10240,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): WRITE: bw=1020MiB/s (1069MB/s), 1020MiB/s-1020MiB/s (1069MB/s-1069MB/s), io=10.0GiB (10.7GB), run=10040-10040msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=write -ioengine=libaio -bs=1m -size=10G -numjobs=1 -group_reporting -name=file16kwrite_seq -runtime 600 file16kwrite_seq: (g=0): rw=write, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=libaio, iodepth=128 fio-3.22 Starting 1 thread file16kwrite_seq: Laying out IO file (1 file / 10240MiB) Jobs: 1 (f=1): [W(1)][-.-%][w=3664MiB/s][w=3663 IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=2746220: Fri Sep 1 04:14:58 2023 write: IOPS=3637, BW=3638MiB/s (3814MB/s)(10.0GiB/2815msec); 0 zone resets slat (usec): min=48, max=2123, avg=95.99, stdev=81.35 clat (usec): min=10955, max=57193, avg=35007.29, stdev=7409.51 lat (usec): min=11040, max=57296, avg=35103.33, stdev=7393.77 clat percentiles (usec): | 1.00th=[19006], 5.00th=[22414], 10.00th=[24511], 20.00th=[28181], | 30.00th=[31327], 40.00th=[33817], 50.00th=[35914], 60.00th=[37487], | 70.00th=[39584], 80.00th=[41681], 90.00th=[43779], 95.00th=[45876], | 99.00th=[50594], 99.50th=[52167], 99.90th=[56361], 99.95th=[56886], | 99.99th=[56886] bw ( MiB/s): min= 3478, max= 3856, per=100.00%, avg=3647.60, stdev=142.16, samples=5 iops : min= 3478, max= 3856, avg=3647.60, stdev=142.16, samples=5 lat (msec) : 20=1.64%, 50=97.20%, 100=1.16% cpu : usr=13.75%, sys=22.35%, ctx=4282, majf=0, minf=2 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.2%, 32=0.3%, >=64=99.4% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=0,10240,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): WRITE: bw=3638MiB/s (3814MB/s), 3638MiB/s-3638MiB/s (3814MB/s-3814MB/s), io=10.0GiB (10.7GB), run=2815-2815msec
1m read libaio No_rand iodepth_128 numjobs_1
fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=read -ioengine=libaio -bs=1m -size=10G -numjobs=1 -group_reporting -name=file16kwrite_seq -runtime 600
LA
[root@ceph192 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=read -ioengine=libaio -bs=1m -size=10G -numjobs=1 -group_reporting -name=file16kwrite_seq -runtime 600 file16kwrite_seq: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=libaio, iodepth=128 fio-3.22 Starting 1 thread Jobs: 1 (f=1): [R(1)][100.0%][r=2231MiB/s][r=2231 IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=52267: Thu Aug 31 03:58:25 2023 read: IOPS=2206, BW=2207MiB/s (2314MB/s)(10.0GiB/4640msec) slat (usec): min=21, max=2917, avg=39.48, stdev=54.37 clat (msec): min=13, max=101, avg=57.81, stdev= 7.07 lat (msec): min=13, max=101, avg=57.85, stdev= 7.06 clat percentiles (msec): | 1.00th=[ 37], 5.00th=[ 50], 10.00th=[ 51], 20.00th=[ 52], | 30.00th=[ 54], 40.00th=[ 56], 50.00th=[ 59], 60.00th=[ 63], | 70.00th=[ 63], 80.00th=[ 64], 90.00th=[ 65], 95.00th=[ 65], | 99.00th=[ 70], 99.50th=[ 77], 99.90th=[ 97], 99.95th=[ 100], | 99.99th=[ 102] bw ( MiB/s): min= 2076, max= 2396, per=99.85%, avg=2203.62, stdev=123.61, samples=9 iops : min= 2076, max= 2396, avg=2203.44, stdev=123.63, samples=9 lat (msec) : 20=0.43%, 50=8.86%, 100=90.68%, 250=0.03% cpu : usr=1.16%, sys=9.89%, ctx=9615, majf=0, minf=6 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.2%, 32=0.3%, >=64=99.4% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=10240,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): READ: bw=2207MiB/s (2314MB/s), 2207MiB/s-2207MiB/s (2314MB/s-2314MB/s), io=10.0GiB (10.7GB), run=4640-4640msec
X86
xuhuai@loongsonlab-56:~$ fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=read -ioengine=libaio -bs=1m -size=10G -numjobs=1 -group_reporting -name=file16kwrite_seq -runtime 60 file16kwrite_seq: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=libaio, iodepth=128 fio-3.33 Starting 1 thread Jobs: 1 (f=1): [R(1)][100.0%][r=848MiB/s][r=847 IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=22070: Thu Aug 31 15:58:35 2023 read: IOPS=913, BW=914MiB/s (958MB/s)(10.0GiB/11209msec) slat (usec): min=46, max=1073, avg=125.84, stdev=57.49 clat (msec): min=43, max=259, avg=139.52, stdev=18.82 lat (msec): min=44, max=259, avg=139.65, stdev=18.81 clat percentiles (msec): | 1.00th=[ 82], 5.00th=[ 108], 10.00th=[ 113], 20.00th=[ 138], | 30.00th=[ 140], 40.00th=[ 142], 50.00th=[ 142], 60.00th=[ 144], | 70.00th=[ 146], 80.00th=[ 148], 90.00th=[ 153], 95.00th=[ 159], | 99.00th=[ 199], 99.50th=[ 203], 99.90th=[ 247], 99.95th=[ 253], | 99.99th=[ 257] bw ( KiB/s): min=813056, max=1196032, per=99.88%, avg=934353.45, stdev=83942.86, samples=22 iops : min= 794, max= 1168, avg=912.45, stdev=81.98, samples=22 lat (msec) : 50=0.18%, 100=1.19%, 250=98.55%, 500=0.08% cpu : usr=1.20%, sys=12.50%, ctx=10238, majf=0, minf=159 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.2%, 32=0.3%, >=64=99.4% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=10240,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): READ: bw=914MiB/s (958MB/s), 914MiB/s-914MiB/s (958MB/s-958MB/s), io=10.0GiB (10.7GB), run=11209-11209msec
X86 2
[root@node-191 ~]# fio -filename=/mnt/mem1/64k -direct=1 -iodepth 128 -thread -rw=read -ioengine=libaio -bs=1m -size=10G -numjobs=1 -group_reporting -name=file16kwrite_seq -runtime 600 file16kwrite_seq: (g=0): rw=read, bs=(R) 1024KiB-1024KiB, (W) 1024KiB-1024KiB, (T) 1024KiB-1024KiB, ioengine=libaio, iodepth=128 fio-3.22 Starting 1 thread Jobs: 1 (f=1): [R(1)][-.-%][r=3083MiB/s][r=3083 IOPS][eta 00m:00s] file16kwrite_seq: (groupid=0, jobs=1): err= 0: pid=2746285: Fri Sep 1 04:15:18 2023 read: IOPS=3155, BW=3156MiB/s (3309MB/s)(10.0GiB/3245msec) slat (usec): min=34, max=644, avg=47.72, stdev=23.46 clat (usec): min=13876, max=80617, avg=40332.98, stdev=3894.56 lat (usec): min=13964, max=80654, avg=40380.77, stdev=3883.77 clat percentiles (usec): | 1.00th=[21627], 5.00th=[38011], 10.00th=[38536], 20.00th=[38536], | 30.00th=[39060], 40.00th=[39584], 50.00th=[40633], 60.00th=[41681], | 70.00th=[41681], 80.00th=[41681], 90.00th=[42206], 95.00th=[42206], | 99.00th=[47973], 99.50th=[64226], 99.90th=[77071], 99.95th=[79168], | 99.99th=[80217] bw ( MiB/s): min= 3058, max= 3314, per=100.00%, avg=3160.67, stdev=102.45, samples=6 iops : min= 3058, max= 3314, avg=3160.67, stdev=102.45, samples=6 lat (msec) : 20=0.78%, 50=98.27%, 100=0.95% cpu : usr=0.49%, sys=15.84%, ctx=10181, majf=0, minf=68 IO depths : 1=0.1%, 2=0.1%, 4=0.1%, 8=0.1%, 16=0.2%, 32=0.3%, >=64=99.4% submit : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.0% complete : 0=0.0%, 4=100.0%, 8=0.0%, 16=0.0%, 32=0.0%, 64=0.0%, >=64=0.1% issued rwts: total=10240,0,0,0 short=0,0,0,0 dropped=0,0,0,0 latency : target=0, window=0, percentile=100.00%, depth=128
Run status group 0 (all jobs): READ: bw=3156MiB/s (3309MB/s), 3156MiB/s-3156MiB/s (3309MB/s-3309MB/s), io=10.0GiB (10.7GB), run=3245-3245msec
paradigm 范例,范式
leverage 杠杆原理,利用
retrieve 取回,弥补,检索
alleviate 减轻,使缓和
dedicated 专注的,献身的
degrade (使)降级,退化
induce 引诱,招致,归纳出
alternate 轮流,替补
heterogeneous 各种各样的,混杂的 非均匀的[计]
skewness 偏度
orthogonal 正交
reside 住,居住,驻留
validate 证明,证实
1. The difference between read/write and pread/pwrite
#include <unistd.h>
ssize_t read(int fd, void *buf, size_t count);
ssize_t write(int fd, const void *buf, size_t count);
ssize_t pread(int fd, void *buf, size_t count, off_t offset);
ssize_t pwrite(int fd, const void *buf, size_t count, off_t offset);
#include <sys/types.h>
#include <unistd.h>
off_t lseek(int fd, off_t offset, int whence);
/* whence
* SEEK_SET: The offset is set to offset bytes
* SEEK_CUR: The offset is set to its current location plus offset bytes
* SEEK_END: The offset is set to the size of the filed plus offset bytes
* since version 3.1, Linux supports additional whence
* SEEK_DATA: Adjust the file offset to the next location in the file
*greater than or equal to offset containing data. If offset points to
*data, then the file offset is set to offset.
* SEEK_HOLE: Adjust the file offset to next hole in the file greater than
*or equal to offset. If offsets points into the middle of a hole, then the
*file offset is set to offset. If there is no hole past offset, then the
*file offset is adjusted to the end of the file(i.e., there is an implicit
*hole at the end of any file).
*/
A hole is a gap within the file for which there are no allocated data blocks.
E.g. a 3KB file contains a 1KB data block followed by a 1KB hole followed by another 1KB data block. When reading over a hole, zeroes will be returned.
进程打开的每个文件都有一个当前文件指针(current file pointer/file offset)指示下次读取和写入的位置。
Pread() works just like read() but reads from the specified position in the file without modifying the file pointer.
This atomicity of pread enables processes or threads that share file descriptors to read from a shared file at a particular offset without using a locking mechanism that would be necessary to achieve the same result in separate lseek and read system calls.
Atomicity is required as the file pointer is shared and one thread might move the pointer using lseek after another process completes an lseek but prior to the read.
--- Stackoverflow-what is the difference between read and pread in unix
lseek + write, pwrite 类似
2. cacheline padding/cacheline alignment
In the context of struct in programming, cacheline padding is a technique used to add additional padding bytes or dummy variables to a struct to align its size with the cacheline size.
Reasons
- Preventing false sharing False sharing occurs when two or more variables that are frequently accessed by different threads or CPU cores are located in the same cache line. When one thread modifies a variable, it may invalidate the cache line and force other threads to reload the entire cache line, even if they are only accessing a different variable within the same cache line.
一言以蔽之,结构中常用的变量独占一个cache行
This technique should be use wisely and only if necessary, too much padding to a struct waste memory and negatively impact cache efficiency.
3. bcache(block cache)
Cache in the Linux kernel's block layer.
Bcache 允许更快的存储设备如SSDs可以作为慢速存储设备HDDs的cache。结合SSDs昂贵的速度和传统HDDs便宜的存储容量,这有效的创建了hybrid volumes并提供性能提升。
Help
This site is build with mdBook.
Use mdBook.